2026-05-22
Capillaries: AMQP 1.0, scalability update
Notable changes since the last scalability testing round:
- AMQP 1.0 support, Capillaries was tested with:
- RabbitMQ 4.3.0
- ActiveMQ Classic 6.2.5
- ActiveMQ Artemis 2.53.0
- more conservative Cassandra LWT use to avoid contention errors (tested with Cassandra 5.0.8)
- sample deployment now uses Ubuntu 26.04

Scalability testing results
And it's time for the traditional scalability check-up, like in 2025, and in 2024. As usual, the portfolio test was used (996 ARK-inspired stock portfolios with 14,683,696 transactions and 713,800 end-of-month holding records).
| Deployment flavor | AWS instance | 4 Cassandra nodes | 8 Cassandra nodes | 16 Cassandra nodes | 32 Cassandra nodes | Cassandra | Daemon | Bastion/RabbitMQ/Prometheus | Total cores | Hourly cost | Total cores | Hourly cost | Total cores | Hourly cost | Total cores | Hourly cost |
|---|---|---|---|---|---|---|---|---|---|---|---|
| aws.arm64.c7g.8 | c7gd.2xlarge | c7g.large | c7g.large | 42 | $1.8141 | 82 | $3.5557 | 162 | $7.0389 | 322 | $14.0053 |
| aws.arm64.c7g.16 | c7gd.4xlarge | c7g.xlarge | c7g.large | 82 | $3.5557 | 162 | $7.0389 | 322 | $14.0053 | ||
| aws.arm64.c7g.32 | c7gd.8xlarge | c7g.2xlarge | c7g.large | 162 | $7.0385 | 322 | $14.0045 | ||||
| aws.arm64.c7g.64 | c7gd.16xlarge | c7g.4xlarge | c7g.large | 322 | $14.0045 |
| Deployment flavor | Cassandra node cores | Cassandra nodes | Run time, s | Cost of run |
|---|---|---|---|---|
| aws.arm64.c7g.8 | 8 | 4 | 903 | $0.46 |
| 8 | 497 | $0.49 | ||
| 16 | 298 | $0.58 | ||
| 32 | 182 | $0.71 | ||
| aws.arm64.c7g.16 | 16 | 4 | 441 | $0.44 |
| 8 | 248 | $0.48 | ||
| 16 | 160 | $0.62 | ||
| aws.arm64.c7g.32 | 32 | 4 | 259 | $0.51 |
| 8 | 144 | $0.56 | ||
| aws.arm64.c7g.64 | 64 | 4 | 151 | $0.59 |
As usual: colors (green, orange, red, black) - to scale up, number of Cassandra nodes (4, 8, 16, 32) - to scale out.
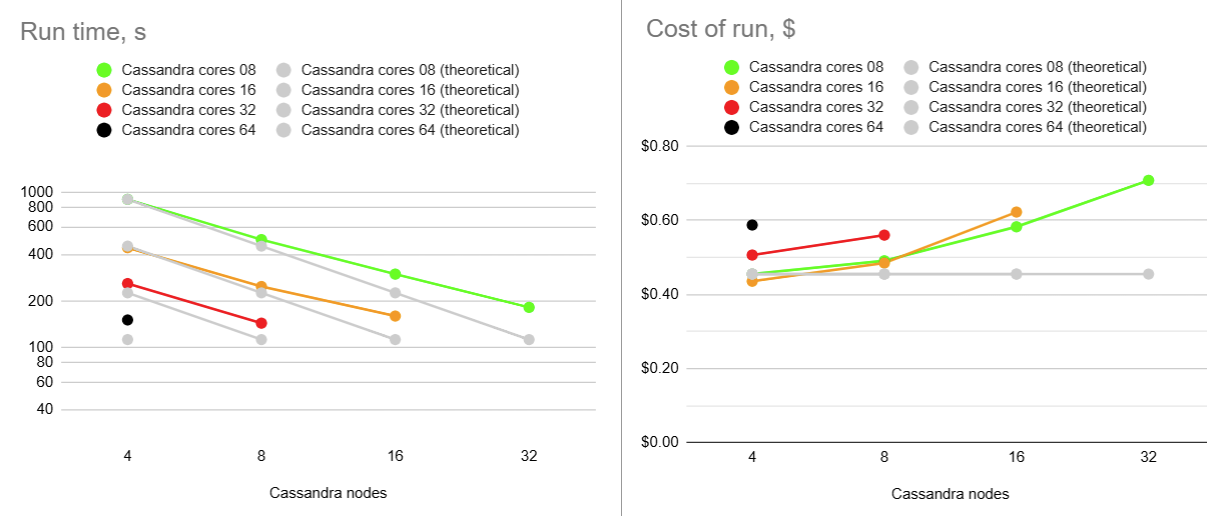
While overall performance numbers show some improvement (probably, thanks to the Cassandra LWT-related changes), scalability patterns remain largely unchanged.
The story behind AMQP 1.0
Some considerations when choosing a message queue engine for Capillaries.
Exactly-once message delivery
This is what we want, ideally. Unfortunately, exactly-once delivery is not a solved problem in the general case, and components that perform actual data processing must be prepared to handle duplicate deliveries and processing component crashes. Minimizing those cases is a good enough goal.
Reasonably low latency
This one is easy - no real-time updates are required. Just make sure data processing components do not sit idle for too long. Capillaries is all about efficient resource utilization.
Standard communication protocol
To minimize vendor lock-in, support a protocol rather than a specific message broker.
Small messages
Capillaries does not pass processed data through the message broker. Messages are therefore almost guaranteed to be smaller than 2 KB.
Queue capacity
A Capillaries data processing node can be split into 100, 1000, or even more batches. A useful Capillaries run will rarely contain more than 20 nodes. A powerful Capillaries deployment could probably handle 100 runs simultaneously.
Each batch requires exactly one message, which means the system may contain up to:
1,000 x 20 x 100 = 2,000,000
messages at any given moment.
Deleyed redelivery
Capillaries assumes retries are essential. Common scenarios include failed data processing components or messages delivered when a node is not yet ready to be processed because its dependency nodes have not completed.
Retry delays must be configurable either globally in the message broker or individually for each returned message.
High availability
Some users cannot afford to re-run part of a Capillaries script simply because the message broker was unavailable for five minutes. Those users are willing to pay for sophisticated clustered broker solutions with strong availability guarantees and a solid reputation.
Platform support
For on-premises deployments, the message broker should support both amd64 and arm64 Linux environments, whether running in Docker containers or virtual machines.
And the winner is...
AMQP 0.9.1 was a solid choice for many years, but the industry appears to be gradually moving toward AMQP 1.0.
The requirements above practically have "AMQP 1.0" written all over them.
An up-to-date list of AMQP brokers is maintained at https://github.com/xinchen10/awesome-amqp.
Among the current leaders are:
On-premises offerings:
- RabbitMQ 4 (maintained by developers at Broadcom)
- Apache ActiveMQ Artemis (maintained by developers at IBM and RedHat)
- Apache ActiveMQ Classic (maintained by developers at Talend)
Cloud offerings:
- Azure Service Bus (although it does not support delayed redelivery)
- Amazon MQ (using either ActiveMQ Classic or RabbitMQ under the hood)
- nothing in GCP?
Now, with AMQP 1.0 as the protocol of choice, which broker should be used for local development and testing?
As of today, Capillaries has been successfully tested with RabbitMQ 4, ActiveMQ Classic, and ActiveMQ Artemis.
At the moment, ActiveMQ Artemis is the primary choice because it feels like a cleaner, more modern successor to Classic-with less legacy code and a simpler configuration model.
All three options require different server-side configurations for redelivery delays, as well as minor client-side differences (for example, Release vs. Reject semantics).
As for cloud-based production deployments, Capillaries should work with both Amazon MQ flavors. It will not work with Azure Service Bus's AMQP 1.0 implementation until delayed redelivery is supported on the server side.