2024-07-17
Capillaries: Terraform deployment, scalability updates, and thread parameters
Scalability numbers
The capillaries-deploy project has been put on hold, Terraform is now the preferred tool for testing Capillaries deployments. Another round of scalability testing was performed. As before, we use setups where:
- number_of_daemons = number_of_cassandra_nodes
- Cassandra nodes are x4 more powerful than Capillaries instances
Here is what has changed since the last round:
- code improvements: async Cassandra writer with no unnecessary buffering; configuration file caching
- updated worker thread and Cassandra writer thread parameters
- RabbitMQ and Prometheus servers now run on the bastion VM (see deployment diagram)
- each test now uses three runs - load, join, and calc - instead of a single run: this makes execution pattern analysis easier
- the GOMEMLIMIT environment variable is now set to prevent OOM errors in high-load scenarios
{kind=link}

As before, portfolio test (996 ARK-inspired stock portfolios with 14,683,696 transactions and 713,800 end-of-month holding records) is used for performance benchmarking. The updated results are presented below.
| Deployment flavor | AWS instance | 4 Cassandra nodes | 8 Cassandra nodes | 16 Cassandra nodes | 32 Cassandra nodes | Cassandra | Daemon | Bastion/RabbitMQ/Prometheus | Total cores | Hourly cost | Total cores | Hourly cost | Total cores | Hourly cost | Total cores | Hourly cost |
|---|---|---|---|---|---|---|---|---|---|---|---|
| aws.arm64.c7g.8 | c7gd.2xlarge | c7g.large | c7g.large | 42 | $1.8141 | 82 | $3.5557 | 162 | $7.0389 | 322 | $14.0053 |
| aws.arm64.c7g.16 | c7gd.4xlarge | c7g.xlarge | c7g.large | 82 | $3.5557 | 162 | $7.0389 | 322 | $14.0053 | ||
| aws.arm64.c7g.32 | c7gd.8xlarge | c7g.2xlarge | c7g.large | 162 | $7.0385 | 322 | $14.0045 | ||||
| aws.arm64.c7g.64 | c7gd.16xlarge | c7g.4xlarge | c7g.large | 322 | $14.0045 |
output_cassandra_cpus = "8 cpus ($0.362900/hr)"
output_cassandra_hosts = 4
output_cassandra_total_cpus = 32
output_daemon_cpus = "2 cpus ($0.072500/hr)"
output_daemon_instances = 4
output_daemon_thread_pool_size = 6
output_daemon_total_cpus = 8
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$1.814100/hr"
output_cassandra_cpus = "8 cpus ($0.362900/hr)"
output_cassandra_hosts = 8
output_cassandra_total_cpus = 64
output_daemon_cpus = "2 cpus ($0.072500/hr)"
output_daemon_instances = 8
output_daemon_thread_pool_size = 6
output_daemon_total_cpus = 16
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$3.555700/hr"
output_cassandra_cpus = "8 cpus ($0.362900/hr)"
output_cassandra_hosts = 16
output_cassandra_total_cpus = 128
output_daemon_cpus = "2 cpus ($0.072500/hr)"
output_daemon_instances = 16
output_daemon_thread_pool_size = 6
output_daemon_total_cpus = 32
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$7.038900/hr"
output_cassandra_cpus = "8 cpus ($0.362900/hr)"
output_cassandra_hosts = 32
output_cassandra_total_cpus = 256
output_daemon_cpus = "2 cpus ($0.072500/hr)"
output_daemon_instances = 32
output_daemon_thread_pool_size = 6
output_daemon_total_cpus = 64
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$14.005300/hr"
output_cassandra_cpus = "16 cpus ($0.725800/hr)"
output_cassandra_hosts = 4
output_cassandra_total_cpus = 64
output_daemon_cpus = "4 cpus ($0.145000/hr)"
output_daemon_instances = 4
output_daemon_thread_pool_size = 12
output_daemon_total_cpus = 16
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$3.555700/hr"
output_cassandra_cpus = "16 cpus ($0.725800/hr)"
output_cassandra_hosts = 8
output_cassandra_total_cpus = 128
output_daemon_cpus = "4 cpus ($0.145000/hr)"
output_daemon_instances = 8
output_daemon_thread_pool_size = 12
output_daemon_total_cpus = 32
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$7.038900/hr"
output_cassandra_cpus = "16 cpus ($0.725800/hr)"
output_cassandra_hosts = 16
output_cassandra_total_cpus = 256
output_daemon_cpus = "4 cpus ($0.145000/hr)"
output_daemon_instances = 16
output_daemon_thread_pool_size = 12
output_daemon_total_cpus = 64
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$14.005300/hr"
output_cassandra_cpus = "32 cpus ($1.451500/hr)"
output_cassandra_hosts = 4
output_cassandra_total_cpus = 128
output_daemon_cpus = "8 cpus ($0.290000/hr)"
output_daemon_instances = 4
output_daemon_thread_pool_size = 24
output_daemon_total_cpus = 32
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$7.038500/hr"
output_cassandra_cpus = "32 cpus ($1.451500/hr)"
output_cassandra_hosts = 8
output_cassandra_total_cpus = 256
output_daemon_cpus = "8 cpus ($0.290000/hr)"
output_daemon_instances = 8
output_daemon_thread_pool_size = 24
output_daemon_total_cpus = 64
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$14.004500/hr"
output_cassandra_cpus = "64 cpus ($2.903000/hr)"
output_cassandra_hosts = 4
output_cassandra_total_cpus = 256
output_daemon_cpus = "16 cpus ($0.580000/hr)"
output_daemon_instances = 4
output_daemon_thread_pool_size = 48
output_daemon_total_cpus = 64
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$14.004500/hr"
| Deployment flavor | Cassandra node cores | Cassandra nodes | Run time, s | Cost of run |
|---|---|---|---|---|
| aws.arm64.c7g.8 | 8 | 4 | 976 | $0.49 |
| 8 | 578 | $0.57 | ||
| 16 | 296 | $0.58 | ||
| 32 | 198 | $0.77 | ||
| aws.arm64.c7g.16 | 16 | 4 | 503 | $0.50 |
| 8 | 275 | $0.54 | ||
| 16 | 176 | $0.68 | ||
| aws.arm64.c7g.32 | 32 | 4 | 270 | $0.53 |
| 8 | 176 | $0.68 | ||
| aws.arm64.c7g.64 | 64 | 4 | 209 | $0.81 |
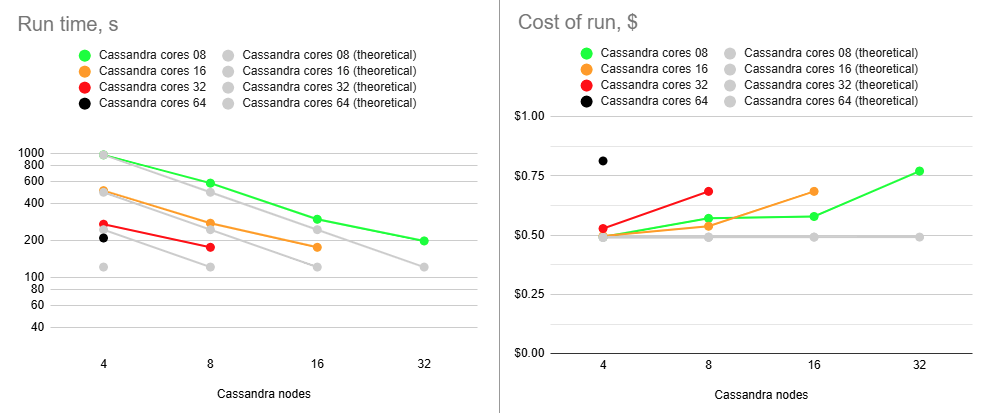
While overall performance numbers have improved, scalability patterns remain largely unchanged.
Choosing thread parameters
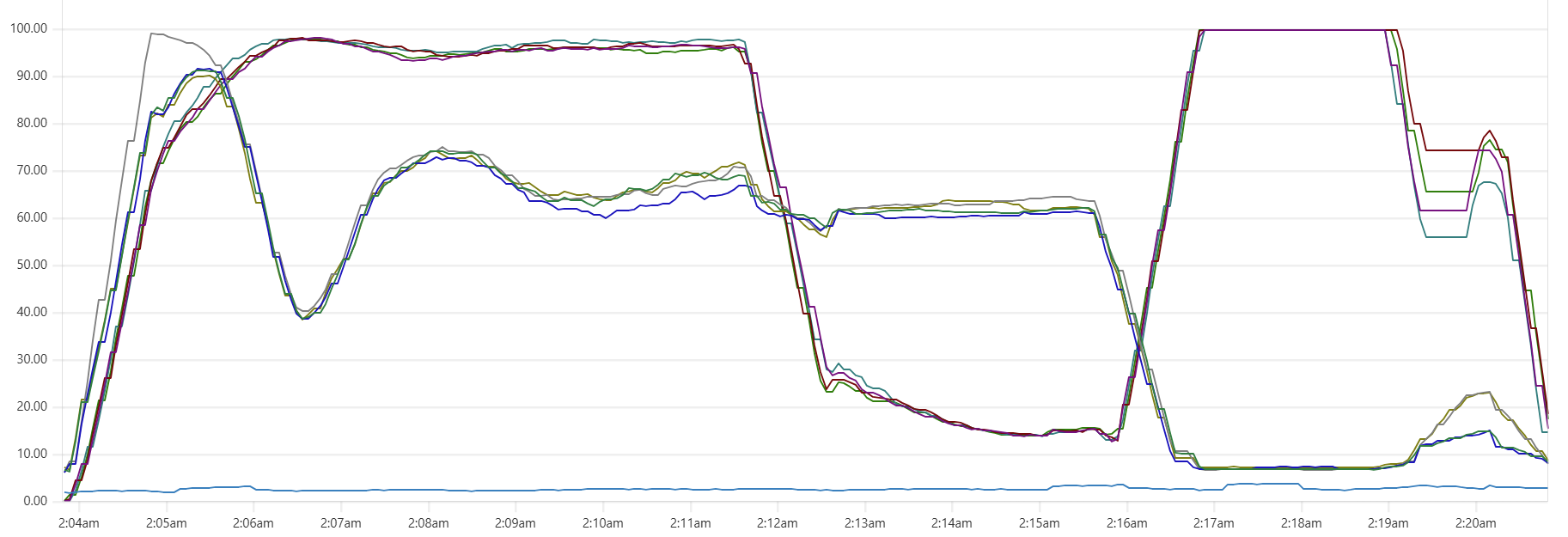
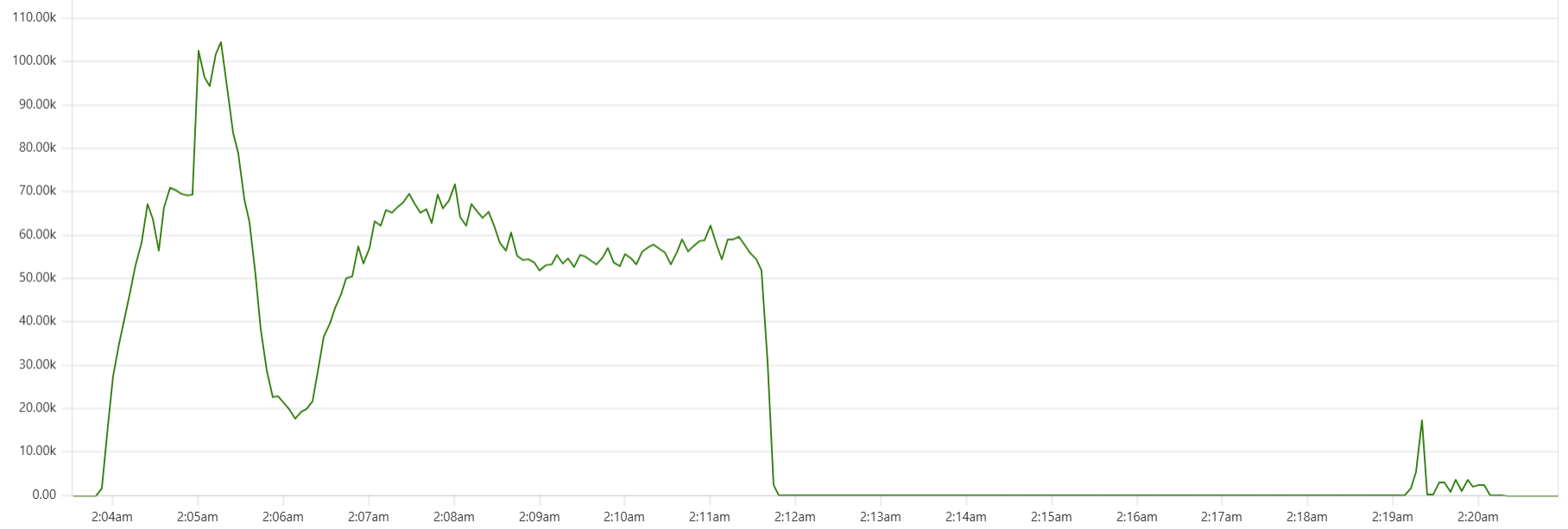
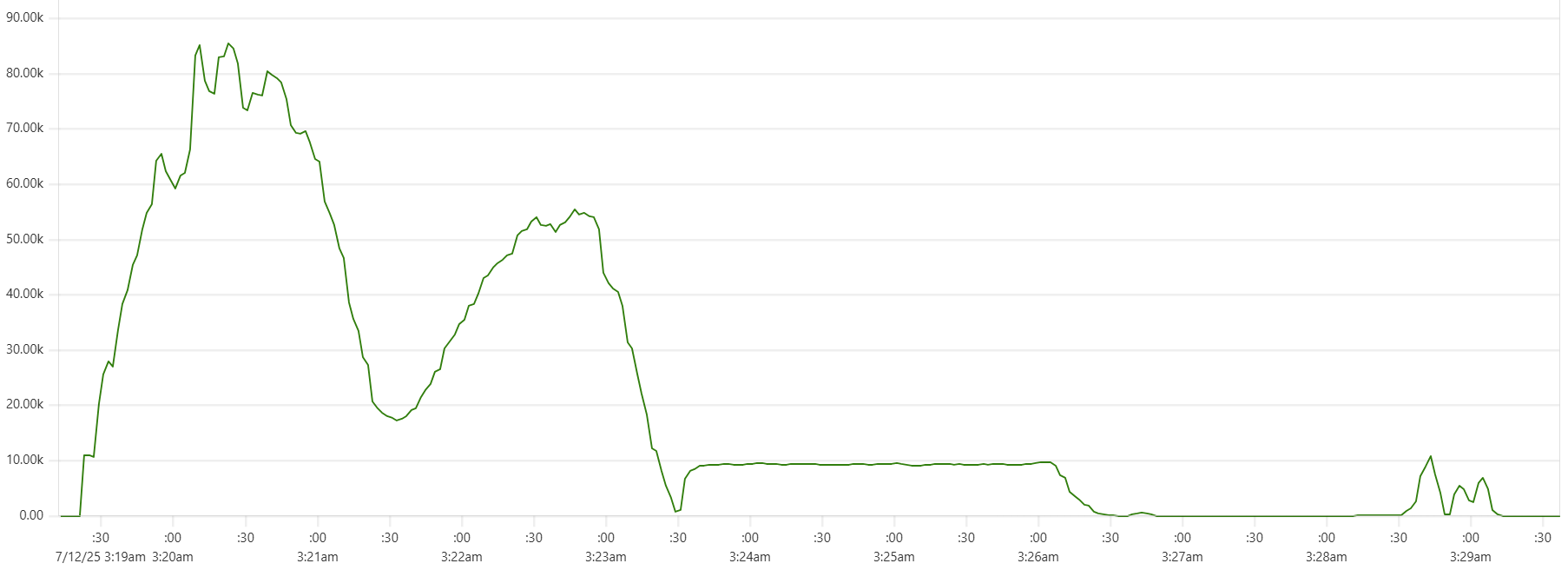
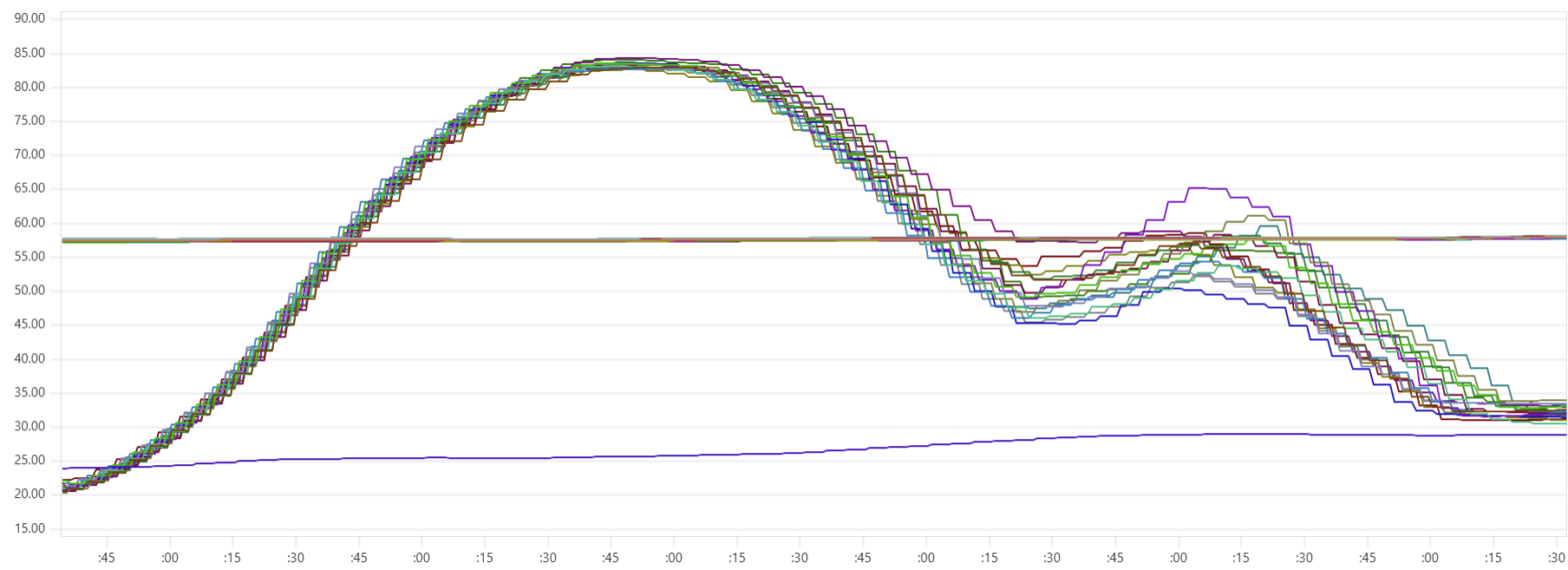
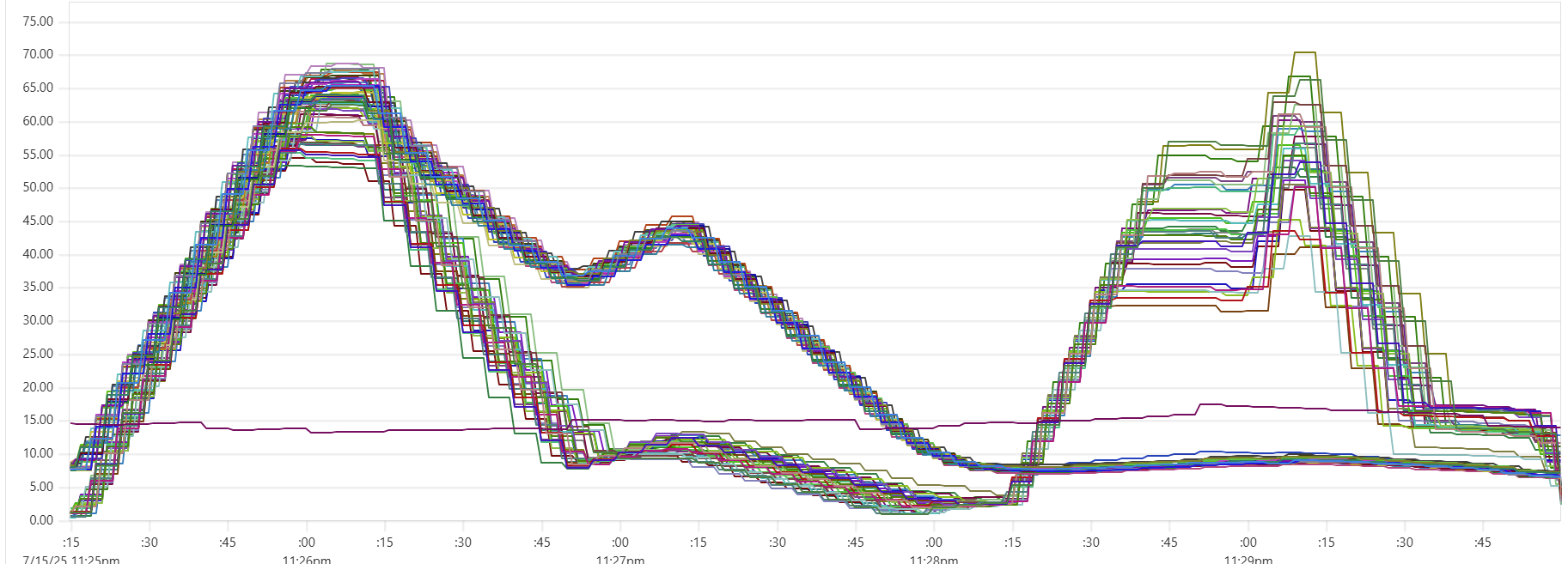
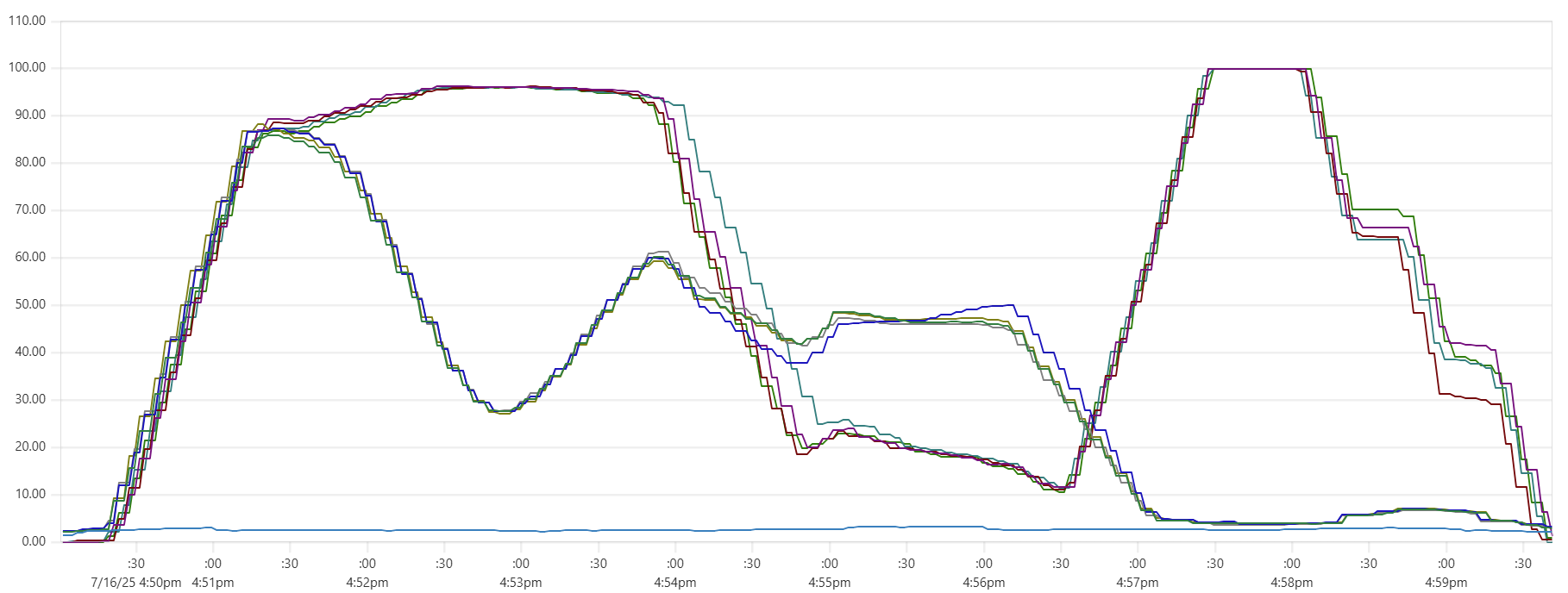
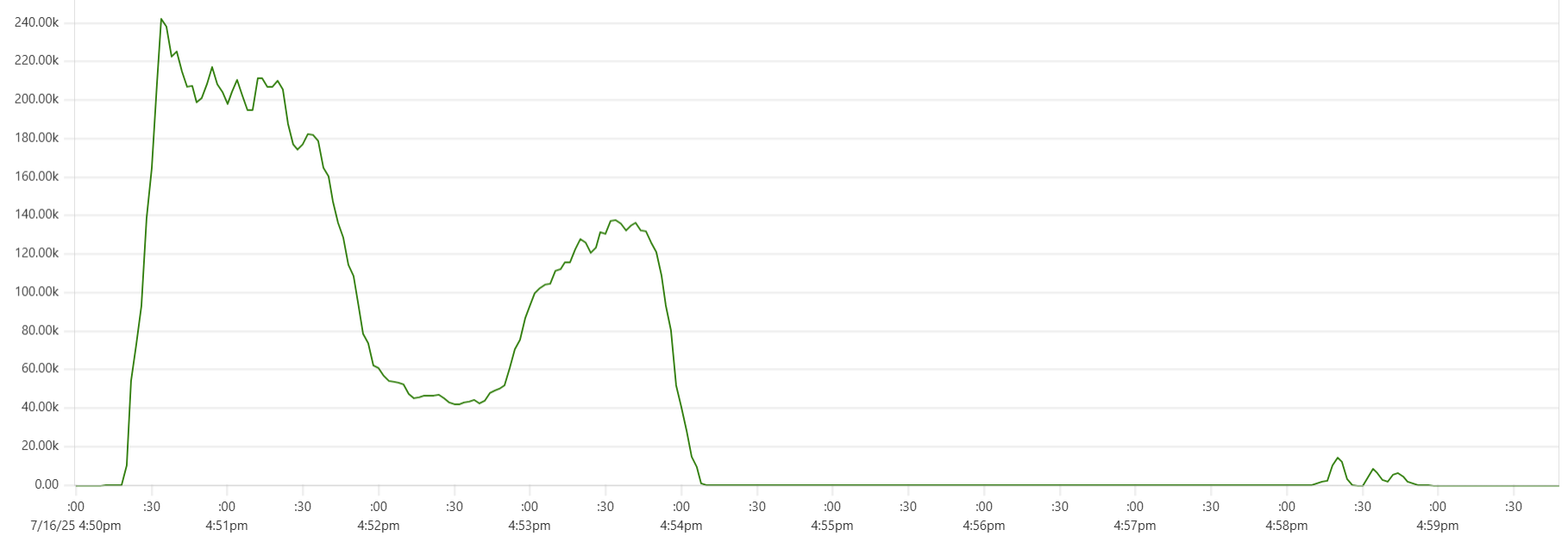
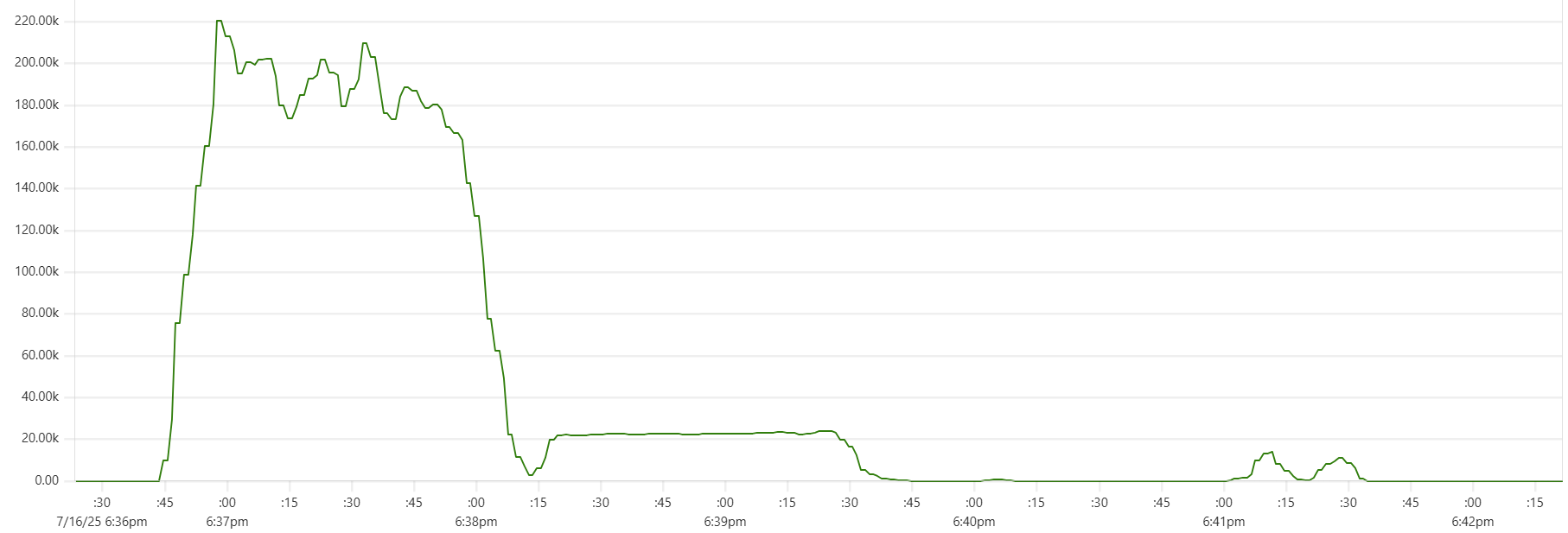
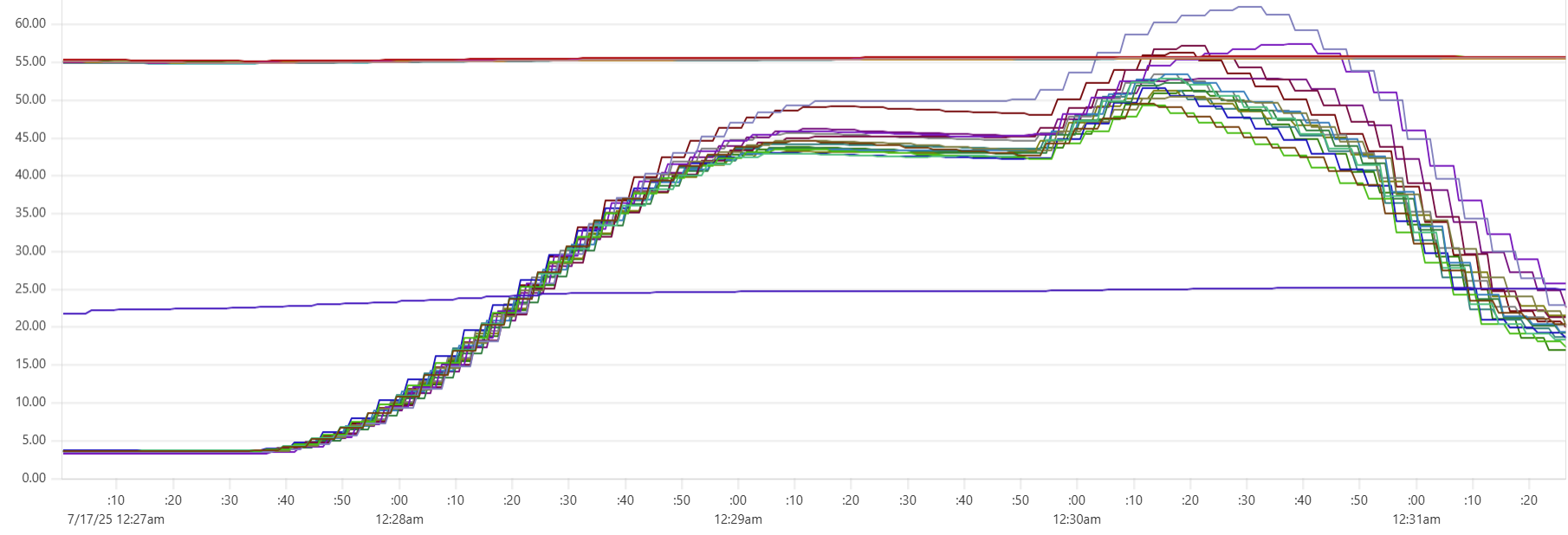
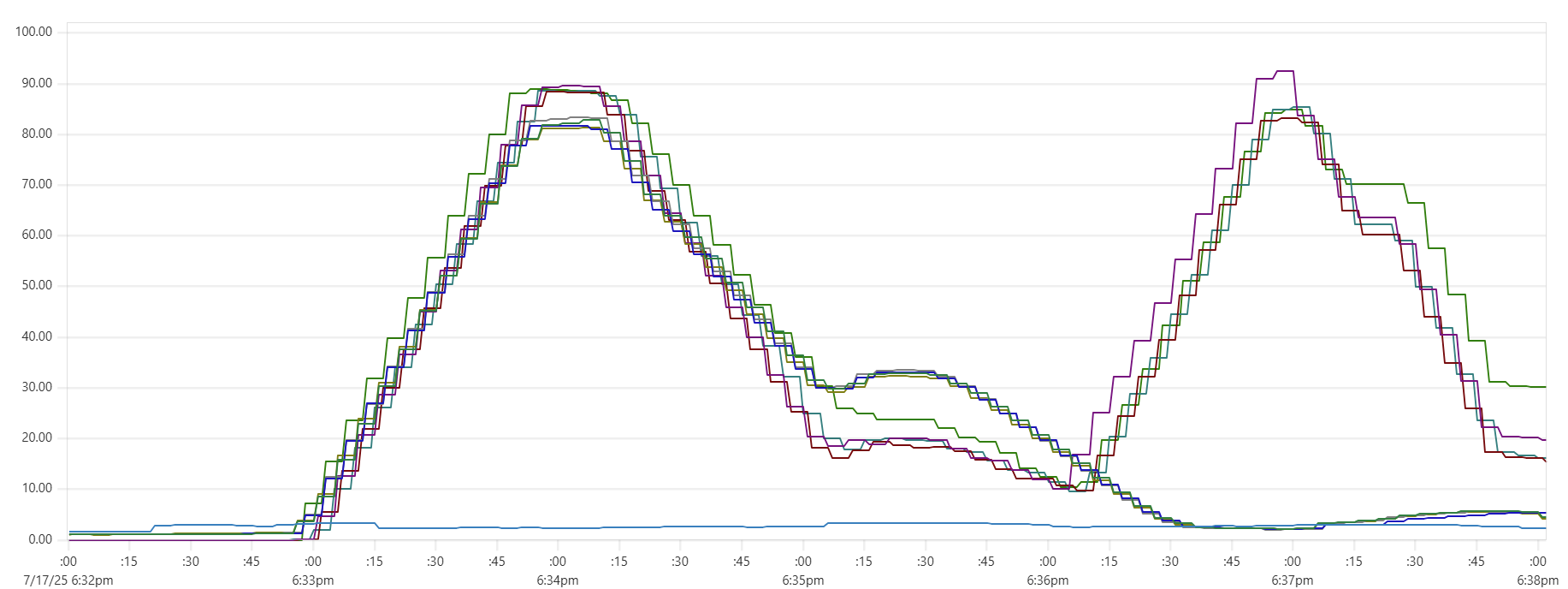
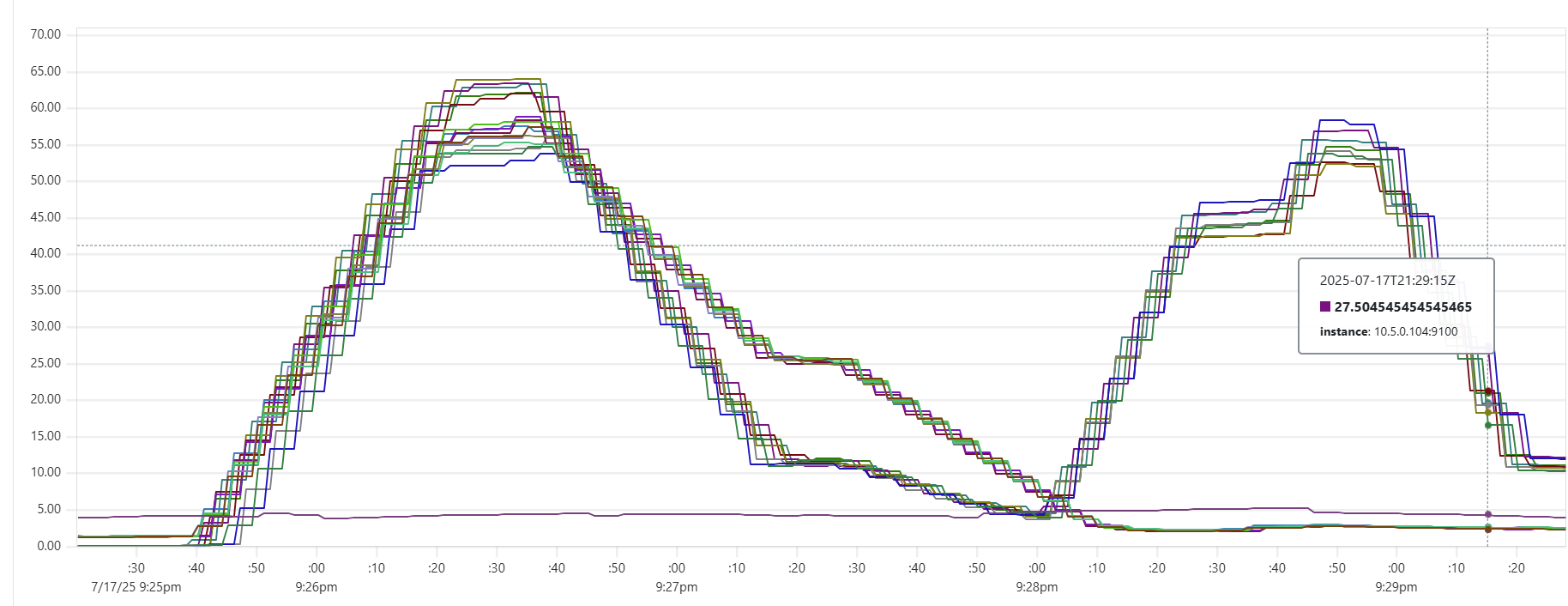
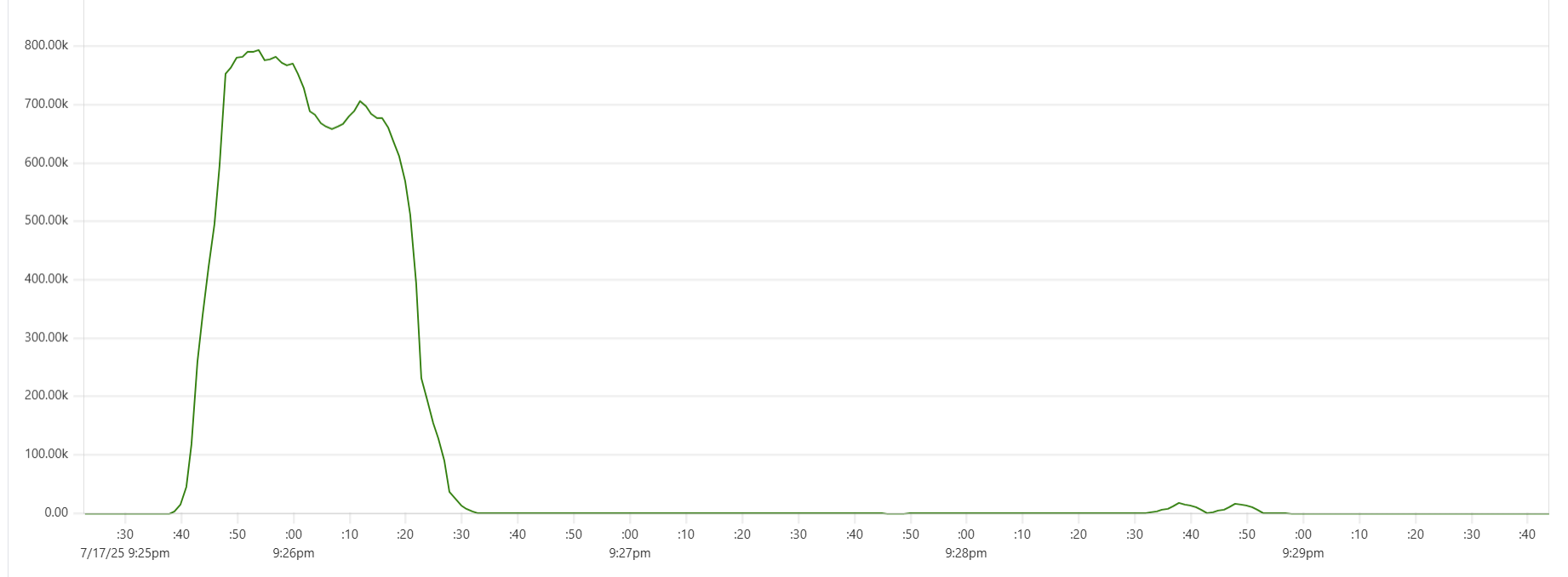
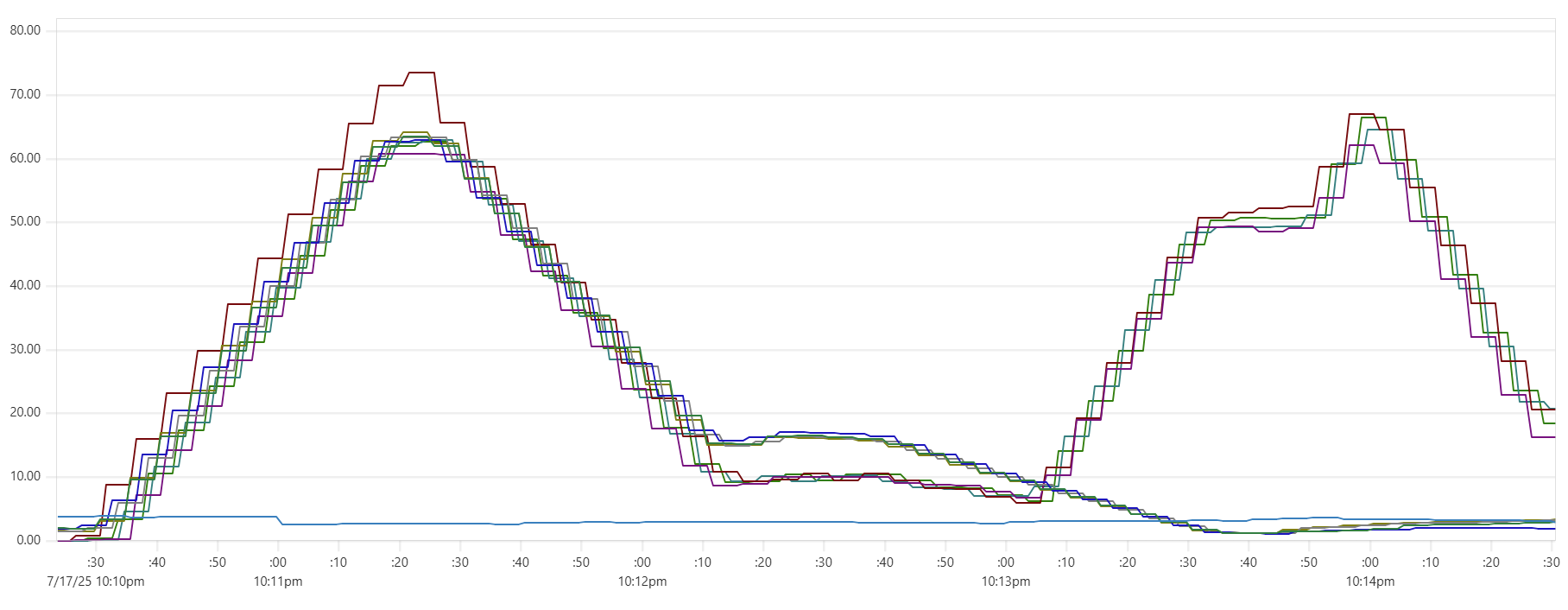
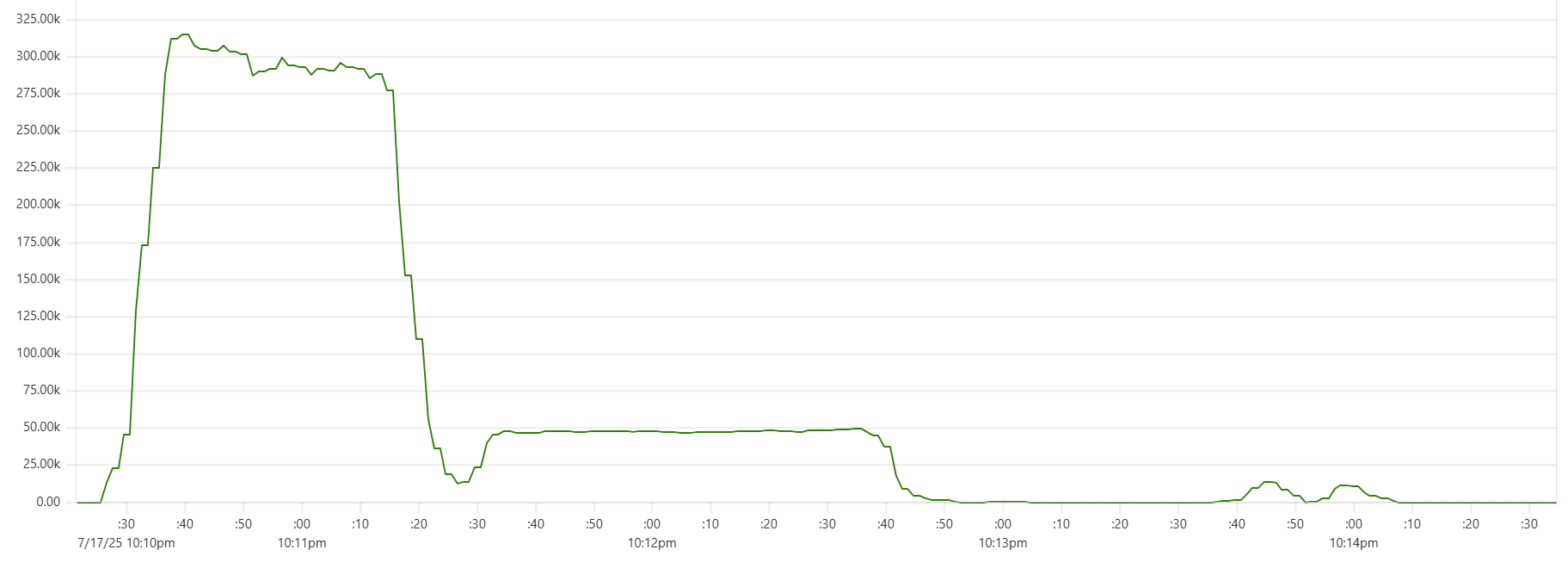
Selecting the thread_pool_size and writer_workers daemon parameters can feel somewhat mysterious. Common sense suggests that thread_pool_size should correlate with the number of CPUs/cores, while writer_workers reflects "how many writes per second my Cassandra cluster can handle". Let's examine a typical CPU usage pattern observed in a low-end VM setup.
There are clearly three zones in this CPU usage pattern:
- load data from file(s) to Cassandra tables: daemon instances run at 95% CPU (good), Cassandra nodes stabilize around 65% (decent)
- joins: daemon CPU usage is low (expected, good), Cassandra is at 60% (decent)
- Python-heavy calculations: daemon CPU usage spikes to 100% (expected, good), Cassandra CPU usage is very low (expected, good)
The objective is to maintain relatively high CPU utilization for both Daemon and Cassandra instances across all 3 zones, while also avoiding situations whenre too many daemon threads are idling - waiting for Cassandra read/write operations to complete. Here are some tuning guidelines.
- "load": the rule is simple: hit Cassandra as hard as you can using write_workers and, while avoiding OOM errors on the daemon side.
- "joins": increasing thread_pool_size from a reasonable "number_of_cores x 1.5" to "number_of_cores x 3" yields good results. Increasing writer_workers beyond a certain point does not help much.
- "Python calculations": keep thread_pool_size above the number_of_cores (but not exessively high). The writer_workers value is largely irrelevant here, so it can be kept low.
In the example shown in the CPU profile above, we used "thread_pool_size = number_of_cores x 3" and "writer_workers = 12":
output_cassandra_cpus = "8 cpus ($0.362900/hr)"
output_cassandra_hosts = 4
output_cassandra_total_cpus = 32
output_daemon_cpus = "2 cpus ($0.072500/hr)"
output_daemon_instances = 4
output_daemon_thread_pool_size = 6
output_daemon_total_cpus = 8
output_daemon_writer_workers = 12
output_daemon_writers_per_cassandra_cpu = 9
output_total_ec2_hourly_cost = "$1.814100/hr"
Why these values? Mainly because they allow us to avoid OOM errors during the "load" phase while maintaining relatively high Casandra CPU usage during both the "load" and "joins" phases.
"thread_pool_size = number_of_cores x 3" may be overkill for the "Python calculations" zone - we could likely achieve similar performance with, say, "thread_pool_size = number_of_cores x 1.5". Howerver, Capillaries is not smart enough to throttle thread_pool_size dynamically based on the type of the transform type.
Is it worth increasing writer_workers to push Cassandra harder? Observations show that increasing writer_workers beyond a certain point yields marginal to negligible improvements.
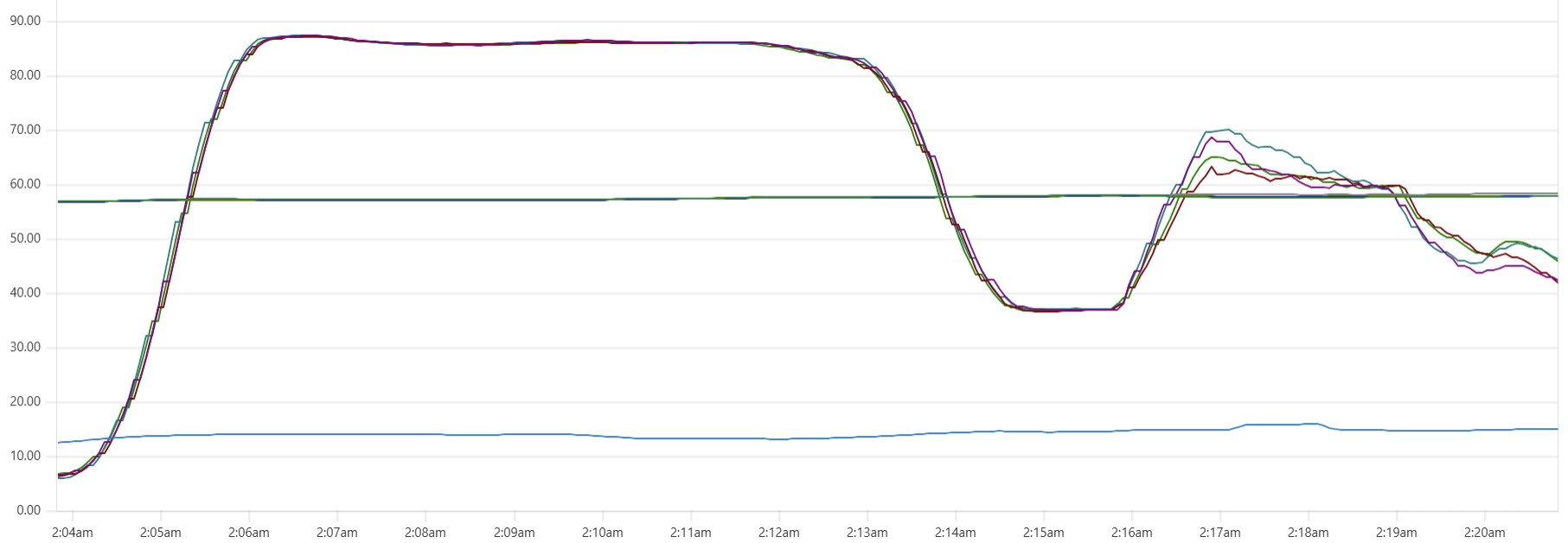
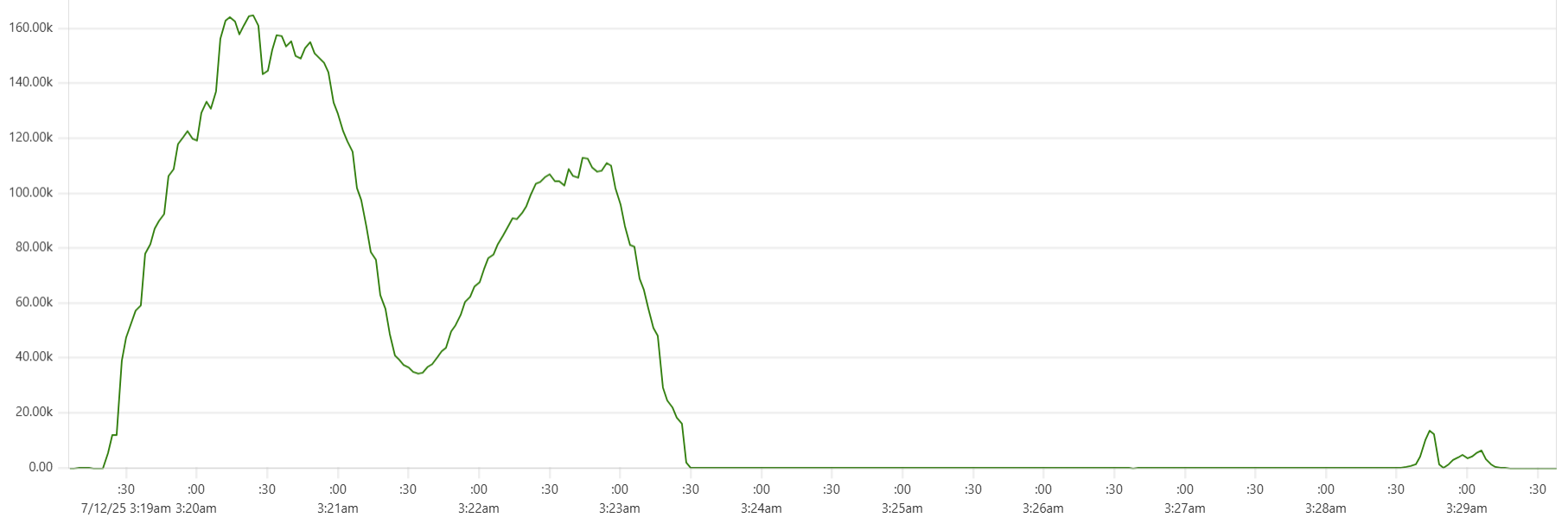
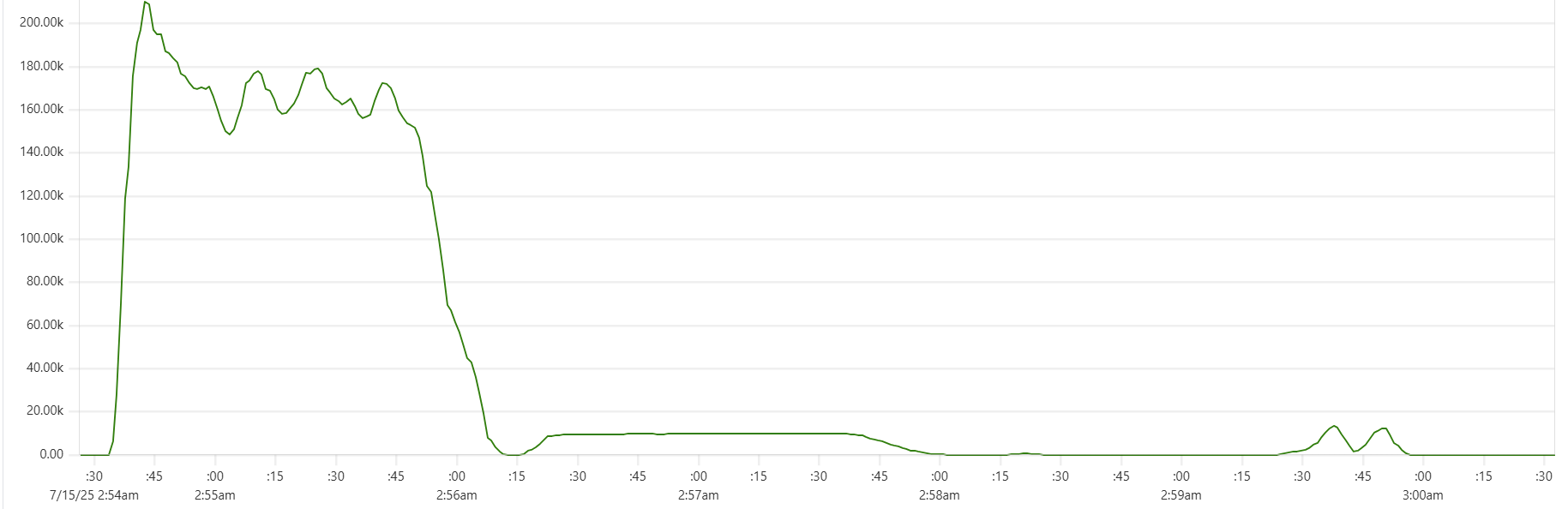
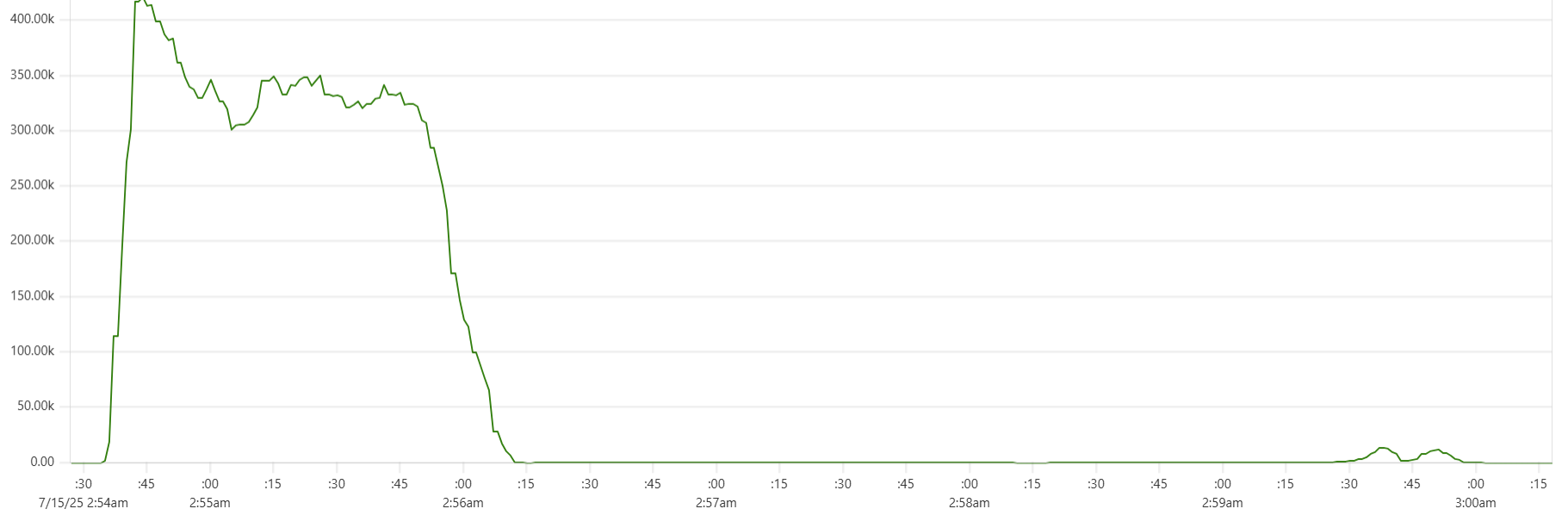
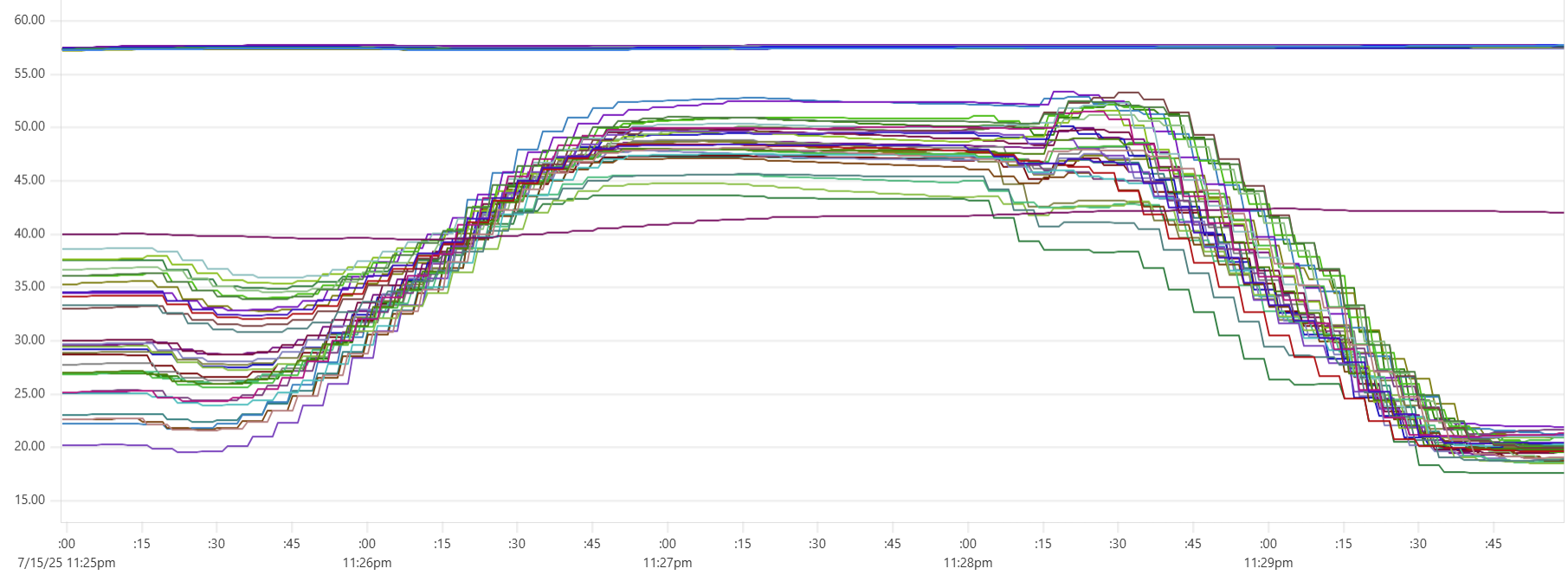
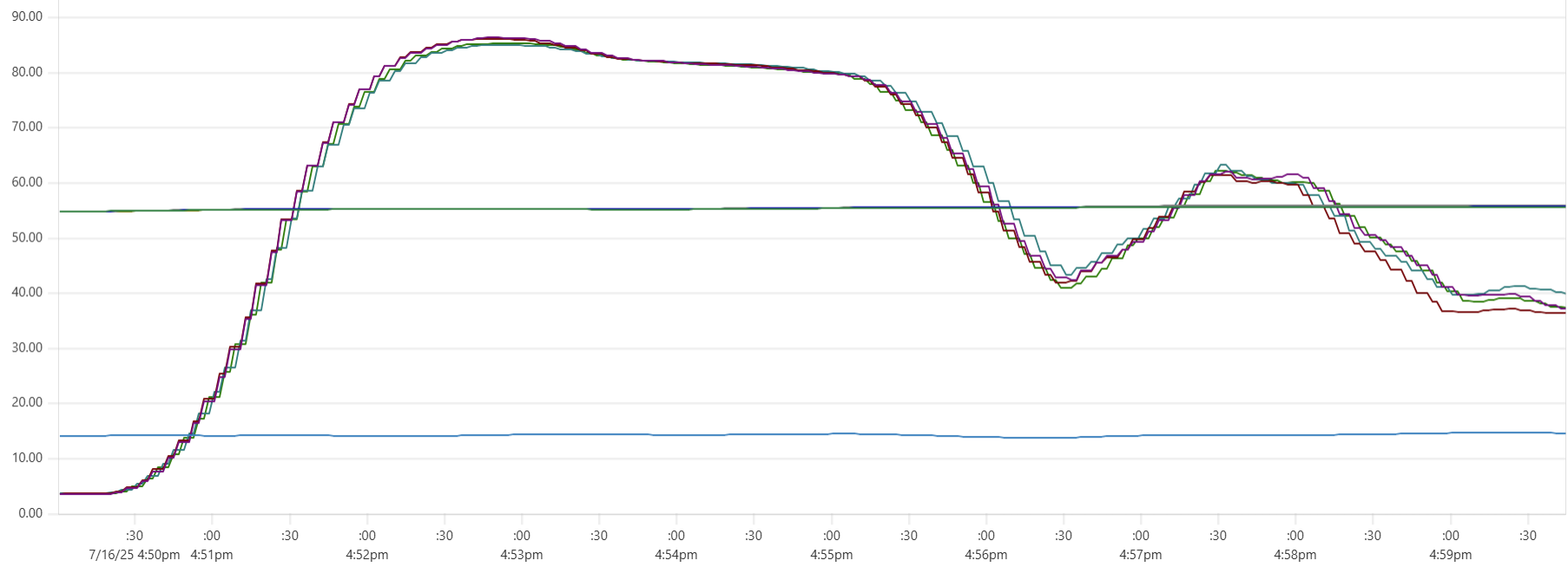
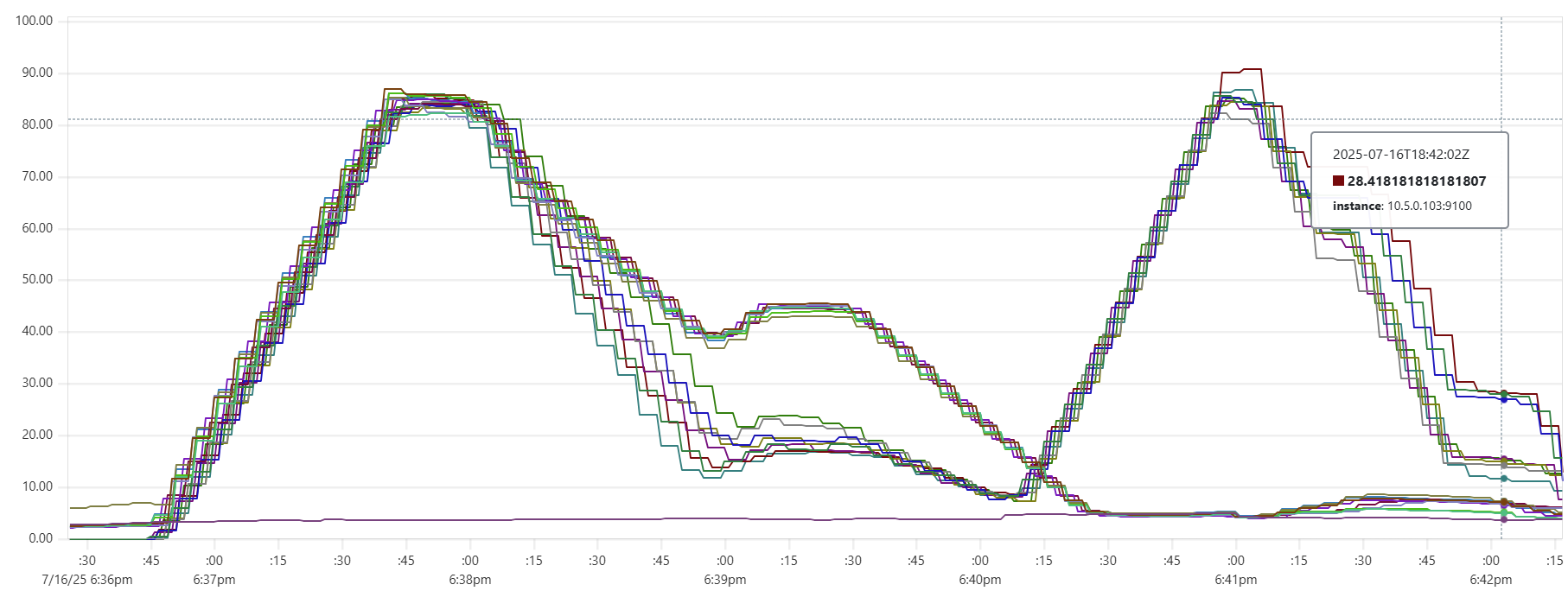
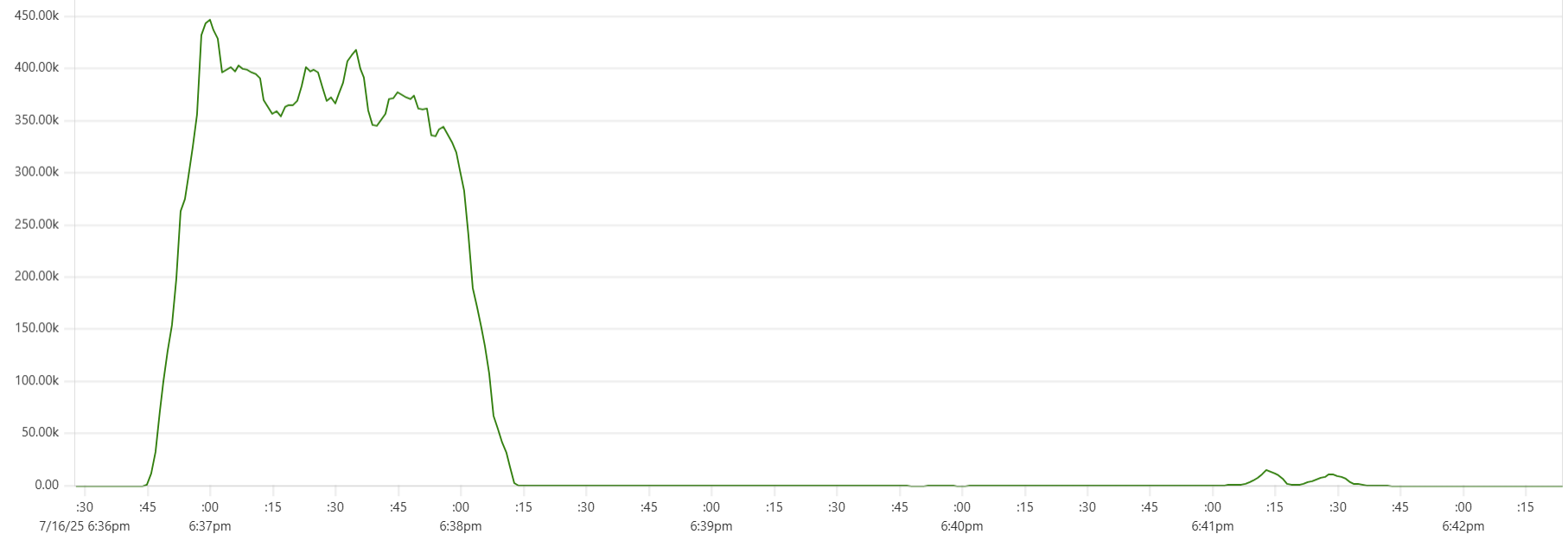
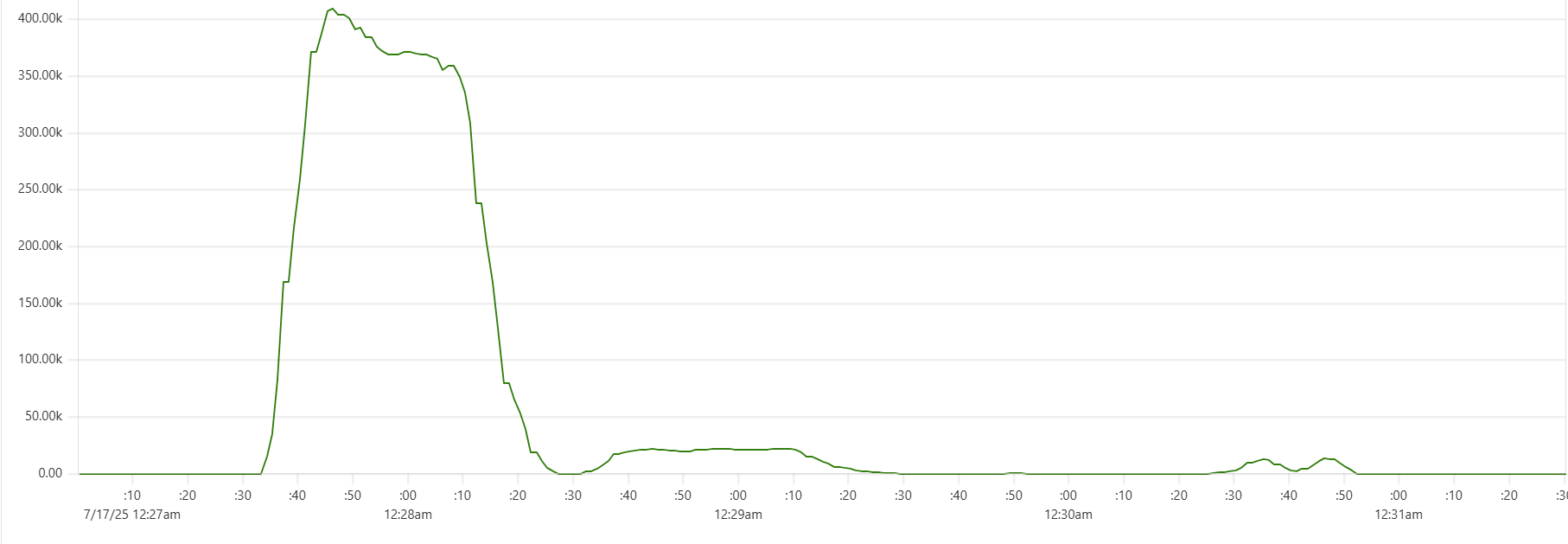
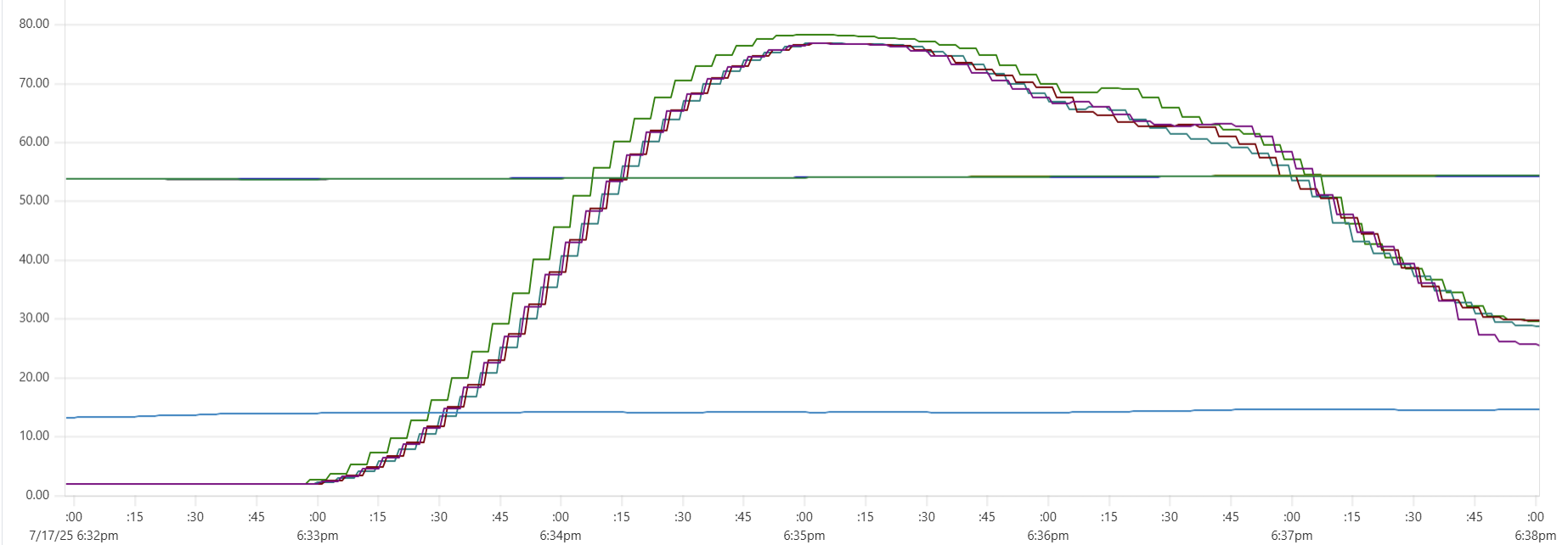
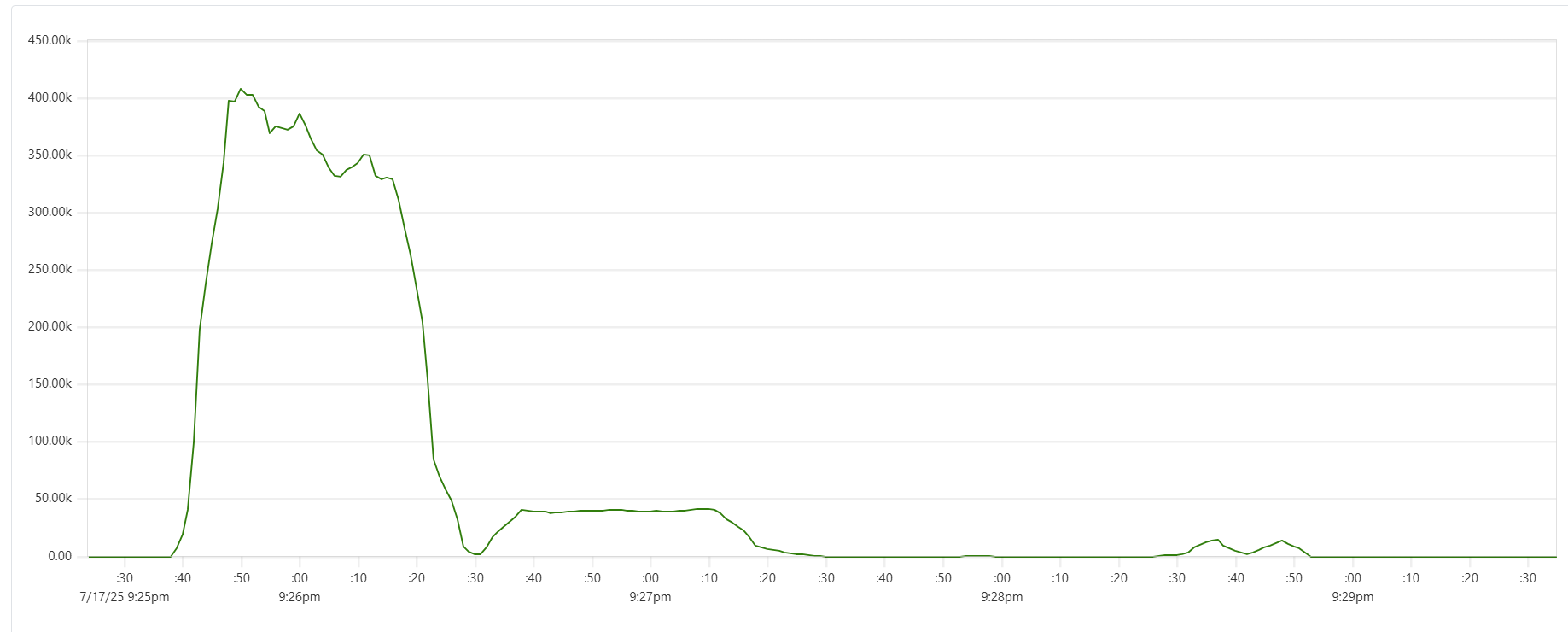
The "Cassandra dip"
There is a noticeable dip starting around 2.05am in Cassandra CPU usage at the start of the "load" phase. My theory is that the start of the dip marks the moment when Capillaries daemon garbage collector kicks in consuming CPU cycles that would otherwise support Cassandra writes. This Prometheus metric - "100 * (1 - ((avg_over_time(node_memory_MemFree_bytes[1m]) + avg_over_time(node_memory_Cached_bytes[1m]) + avg_over_time(node_memory_Buffers_bytes[1m])) / avg_over_time(node_memory_MemTotal_bytes[1m])))" - shows memory usage, and memory consumption hits the ceiling around 2:06am:
For this test, GOMEMLIMIT was set to 75% of total RAM. However, because this is a soft limit (and there are other processes besides Capillaries daemon running on each instance), daemon memory consumption stabilizes around 85%. While this may be aggressive for production environments, it makes sense for performance testing.
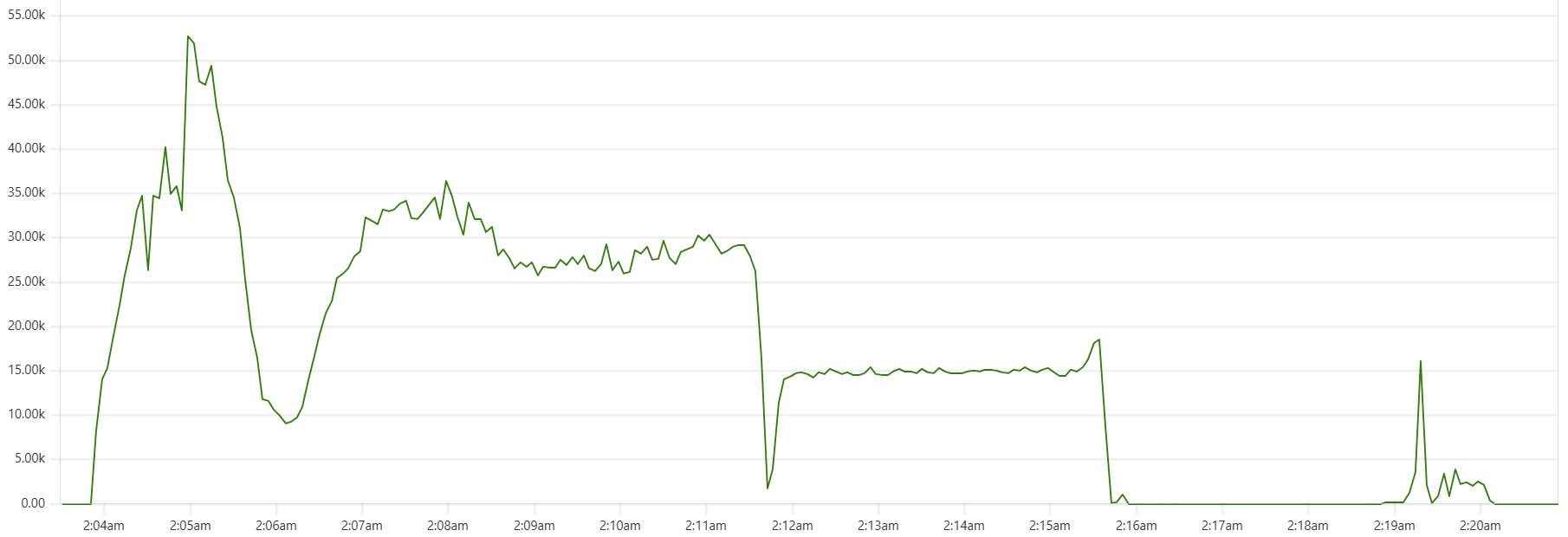
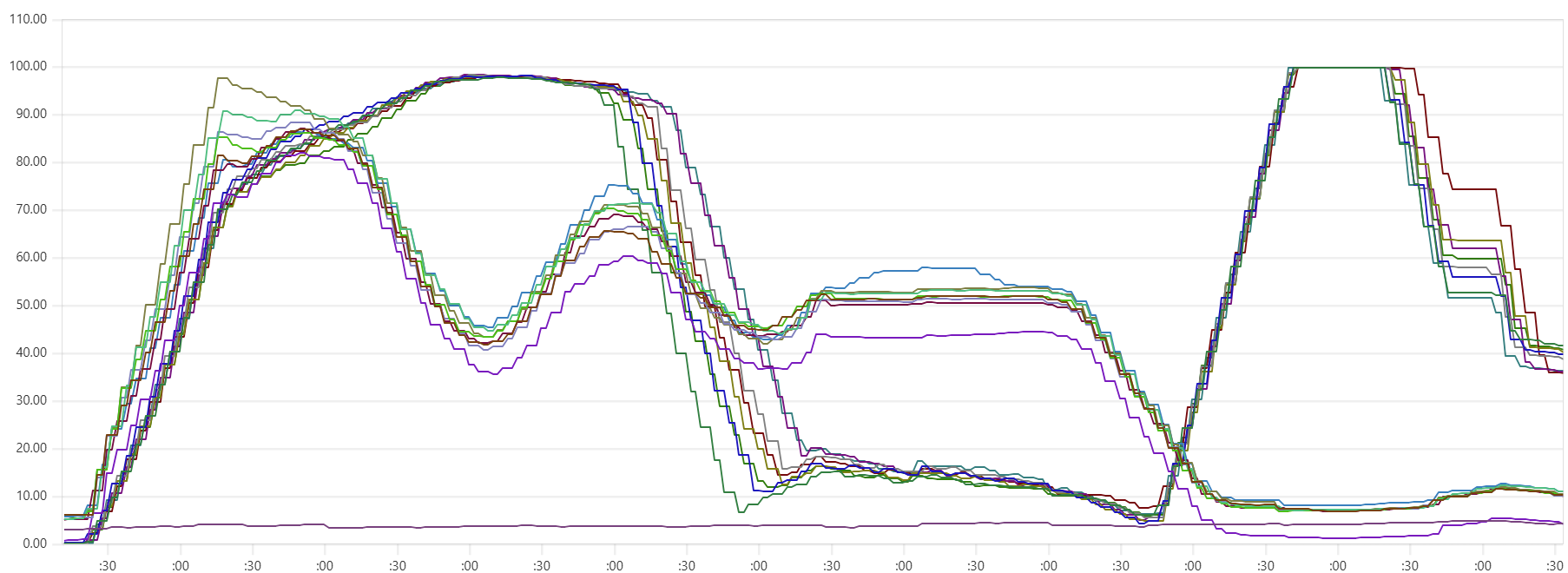
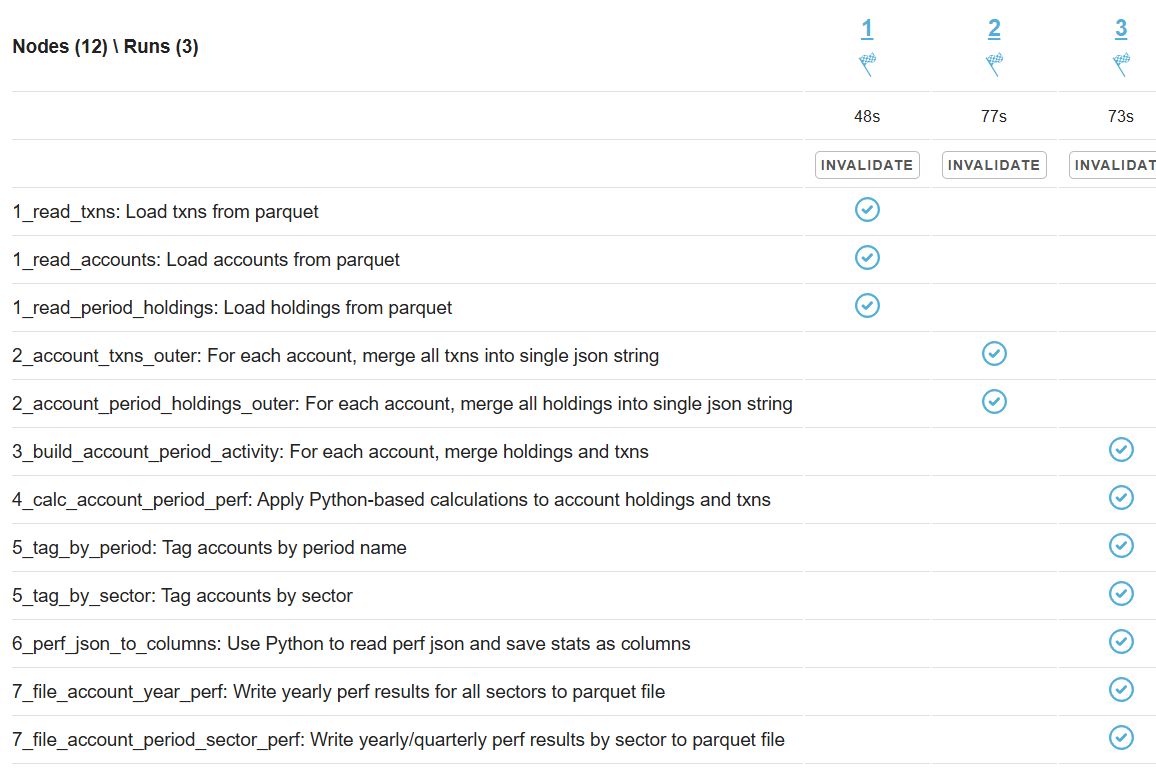
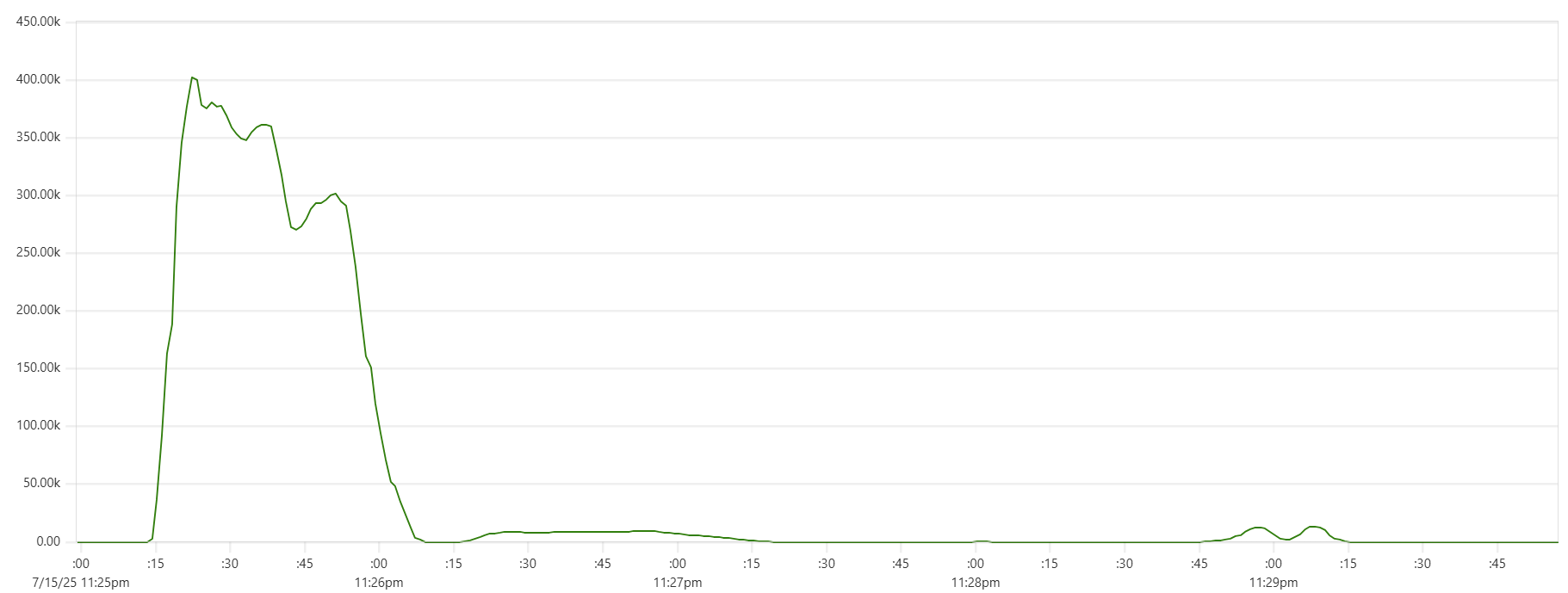
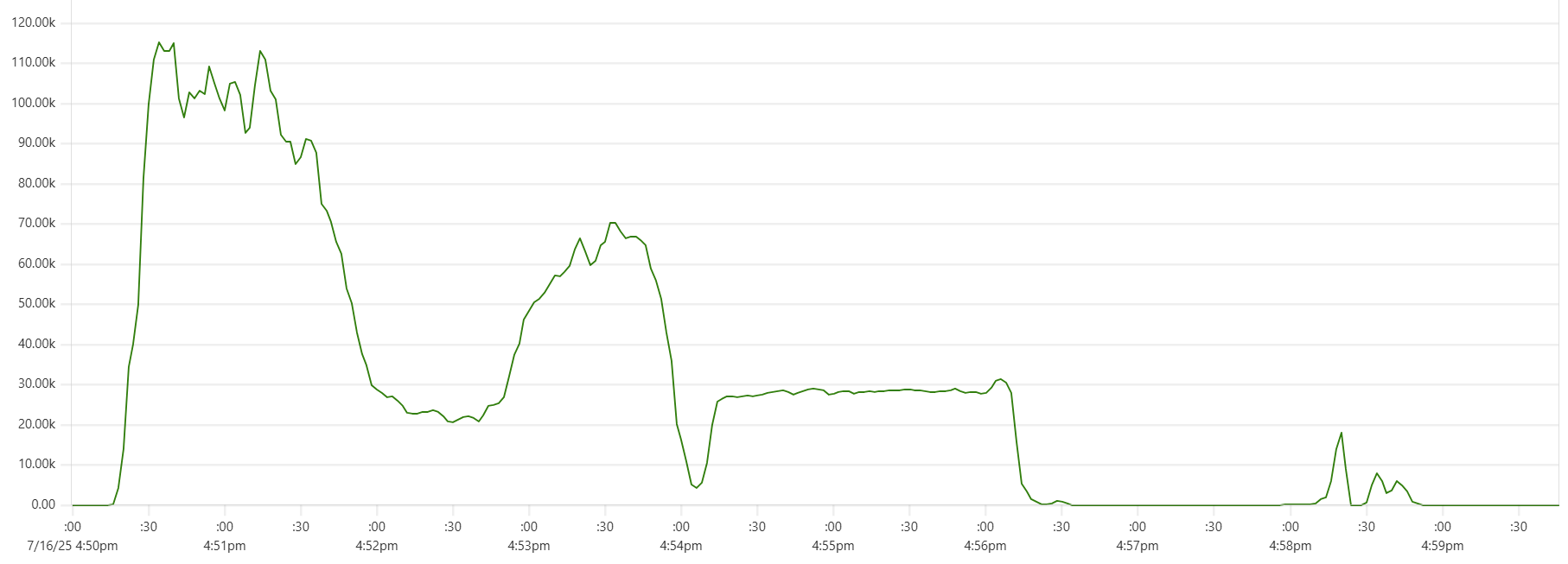
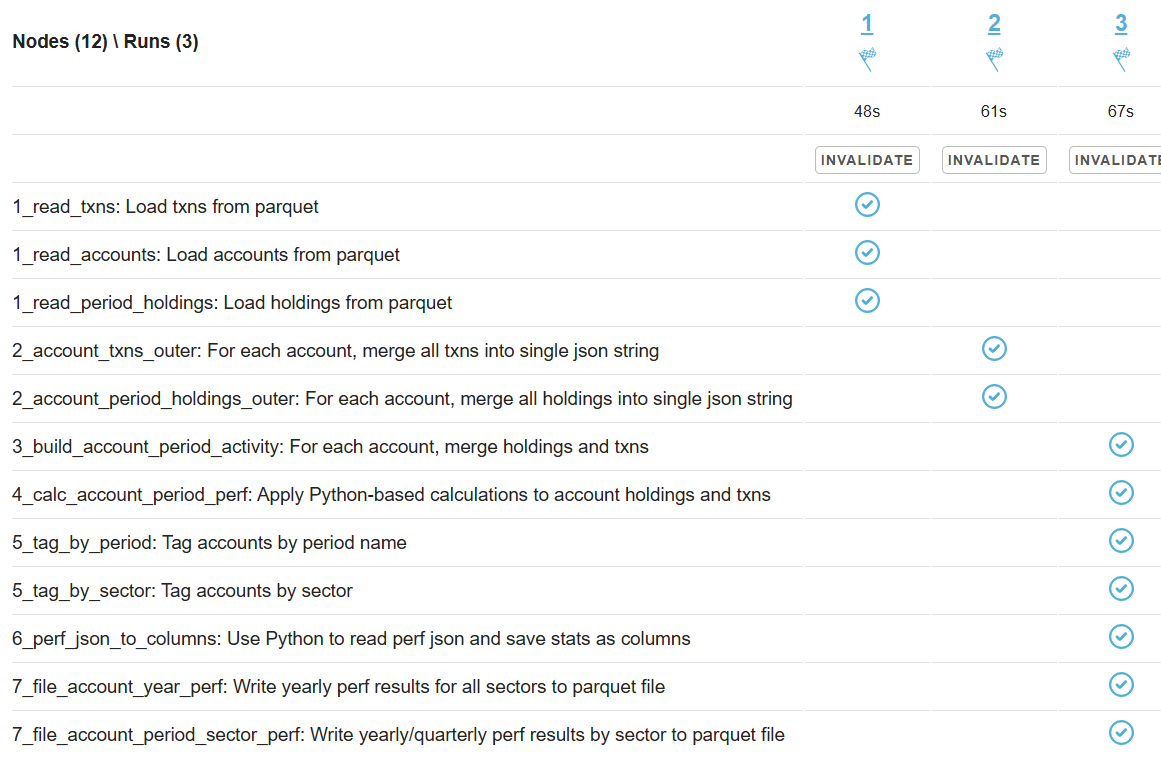
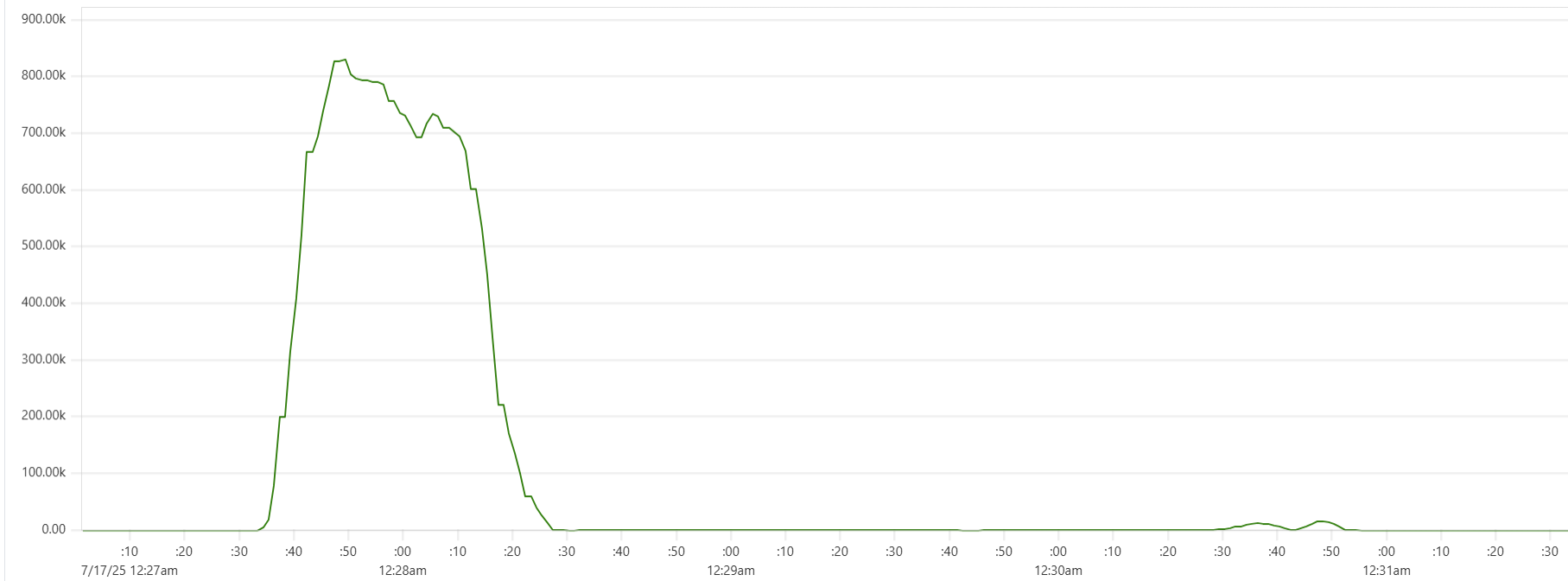
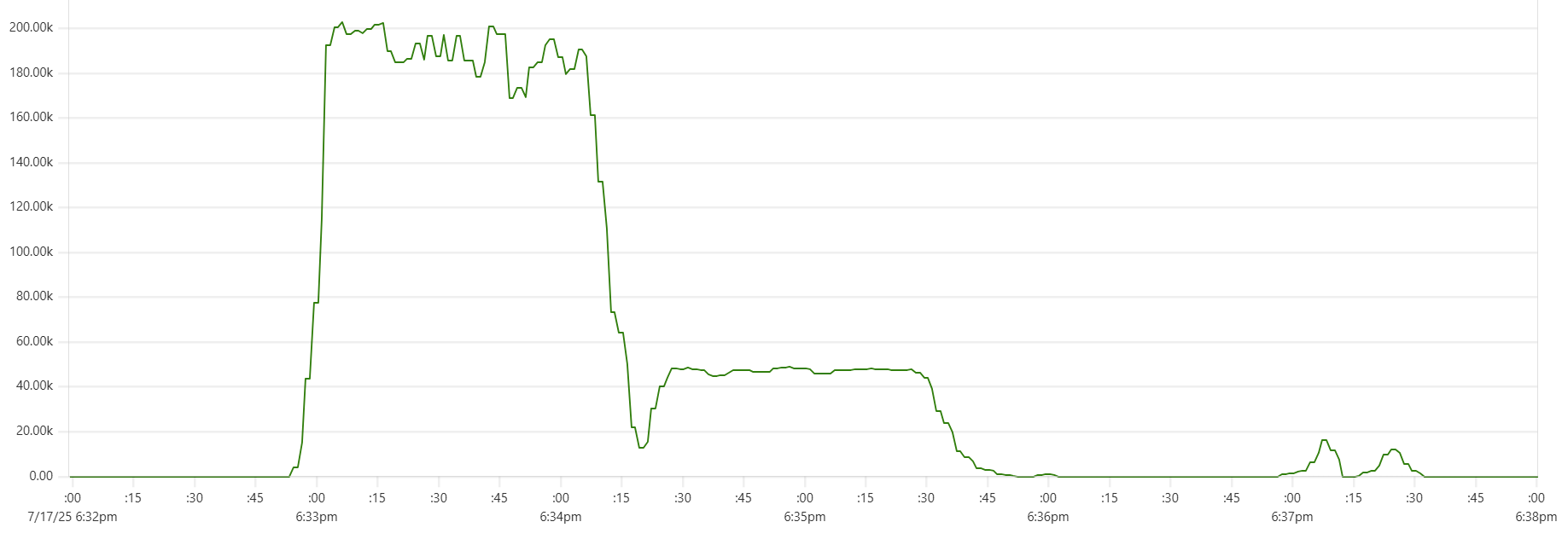
Another sign of GC starting to actively release memory on daemon instances - batch processing time increase, see Capillaries node batch history view:

As daemon memory consumption stabilizes on the plateau, Cassandra CPU usage picks up and batch processing time goes back to smaller values.
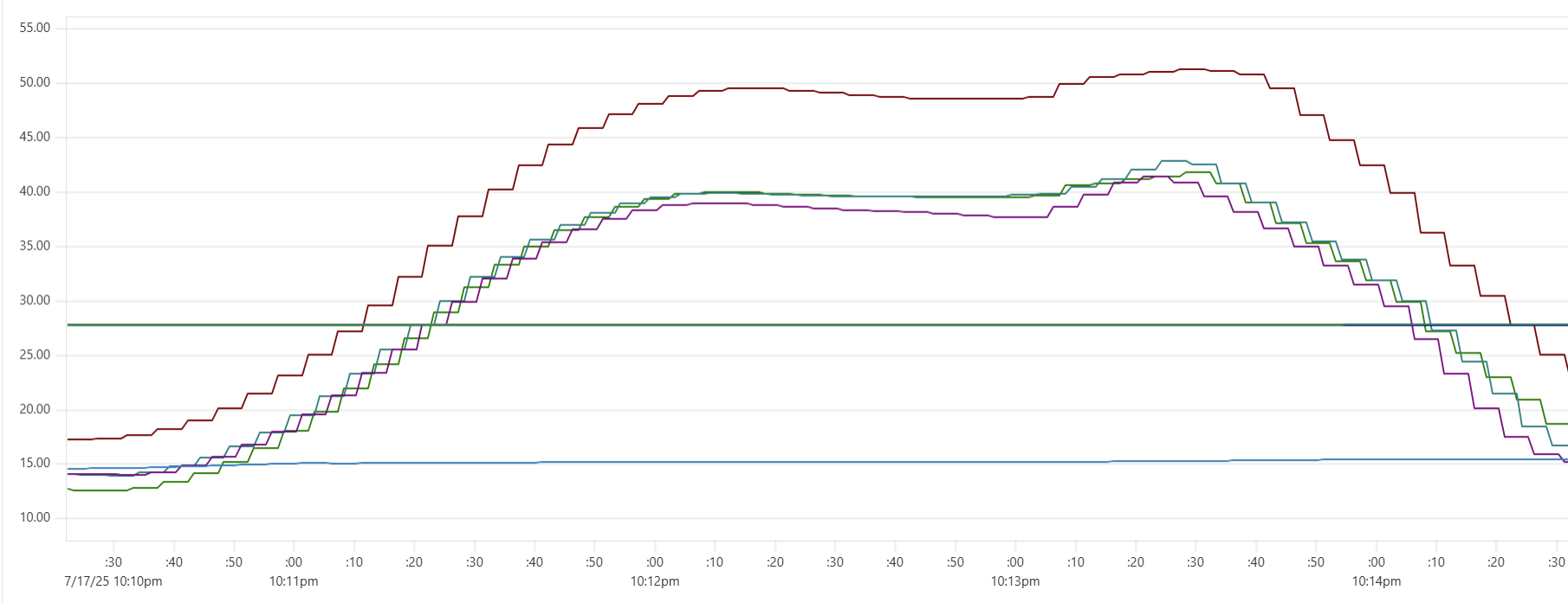
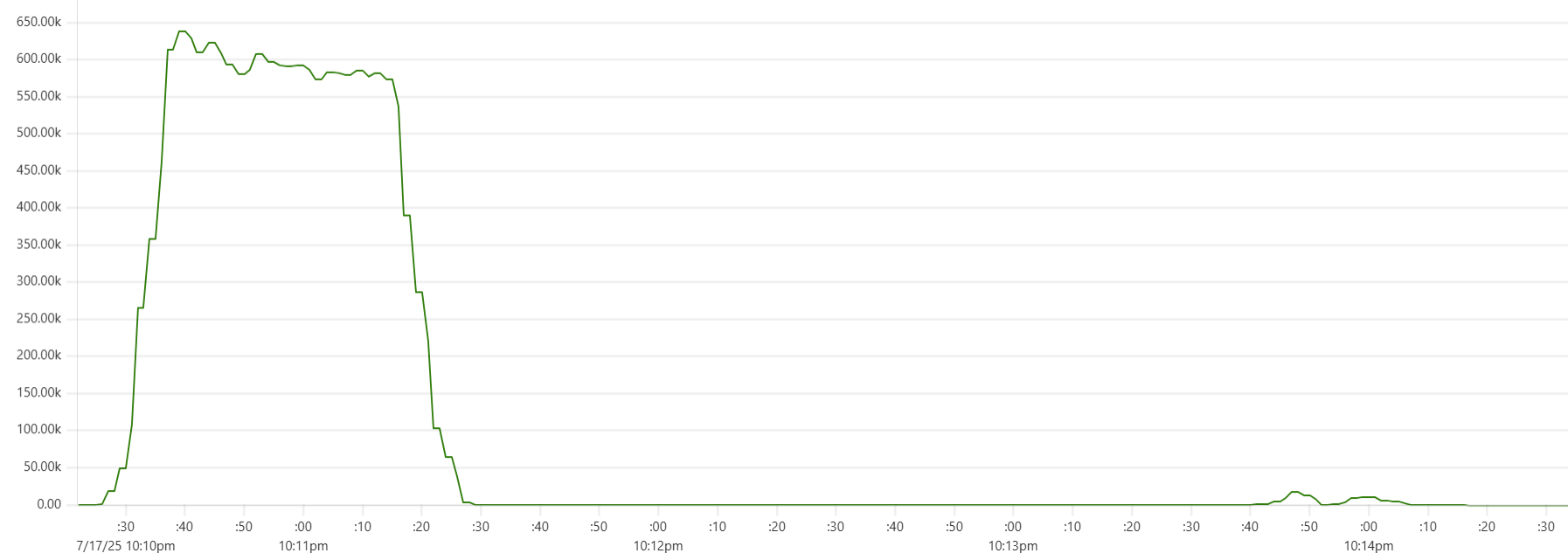
Powerful setups: performance degradation?
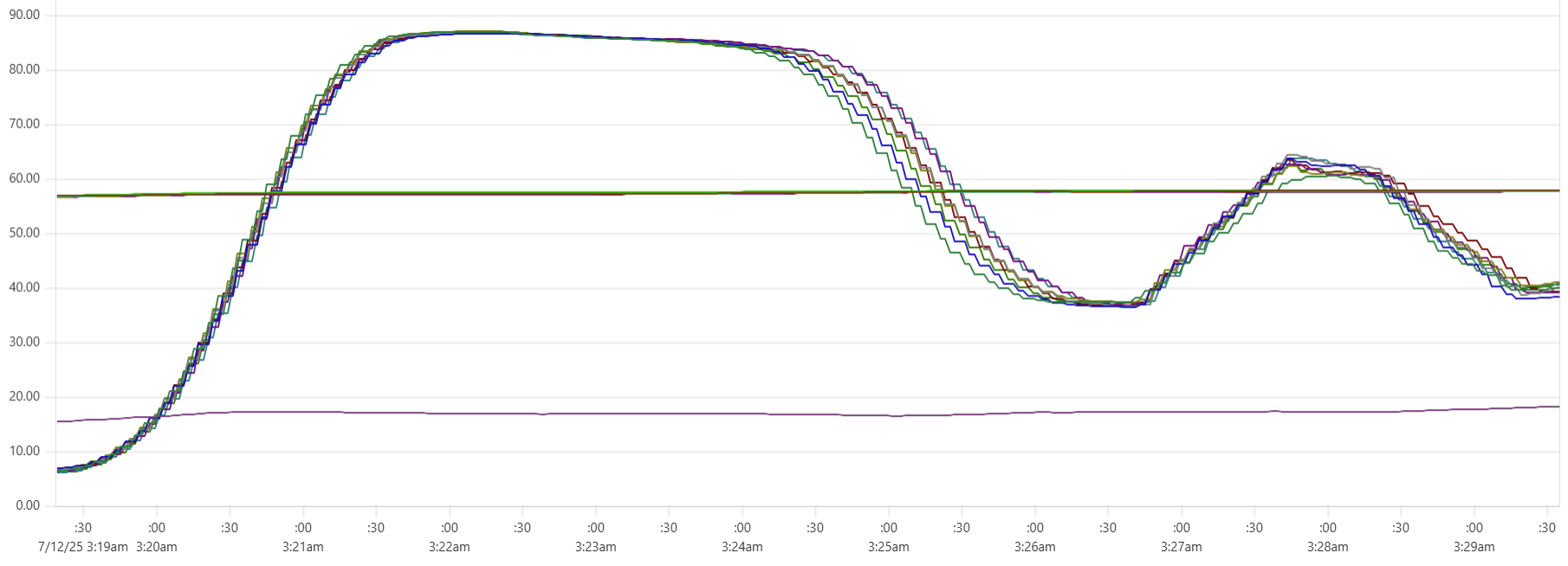
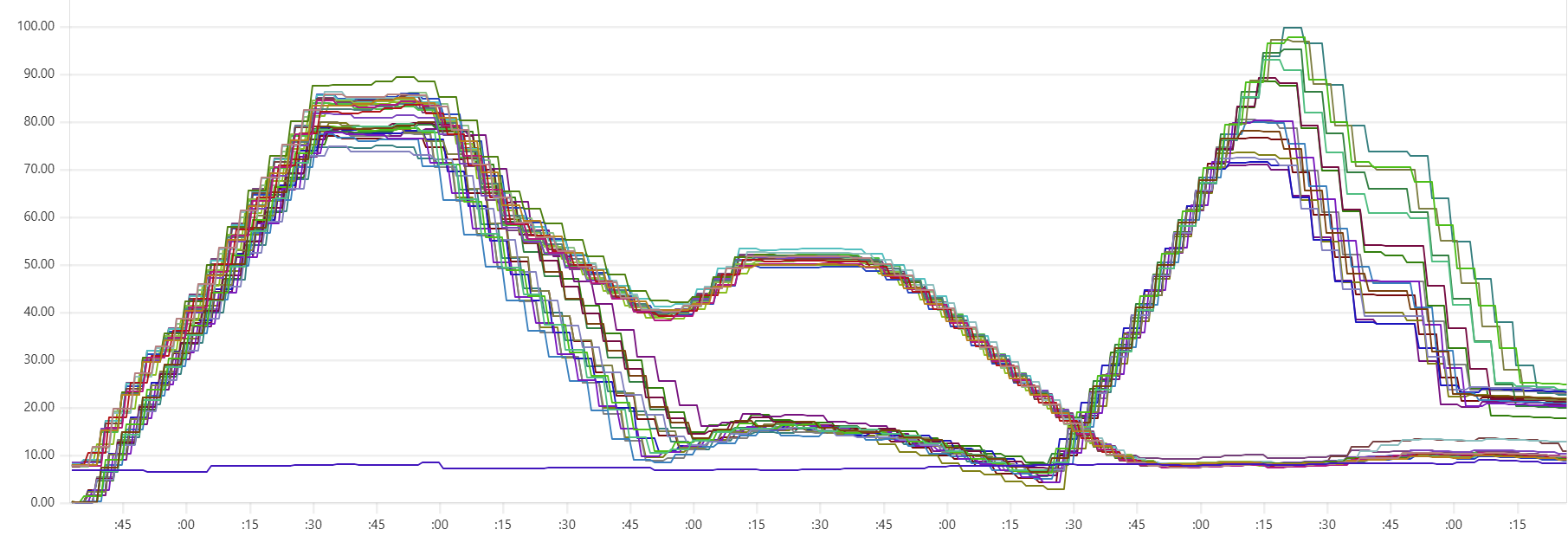
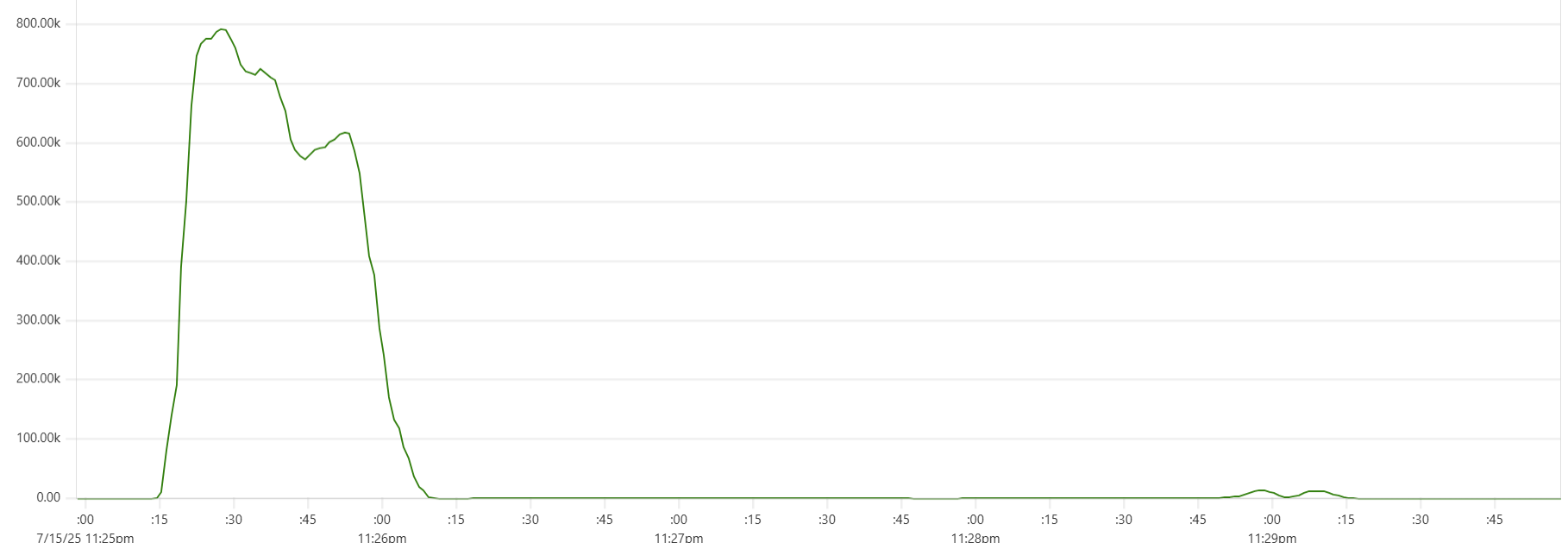
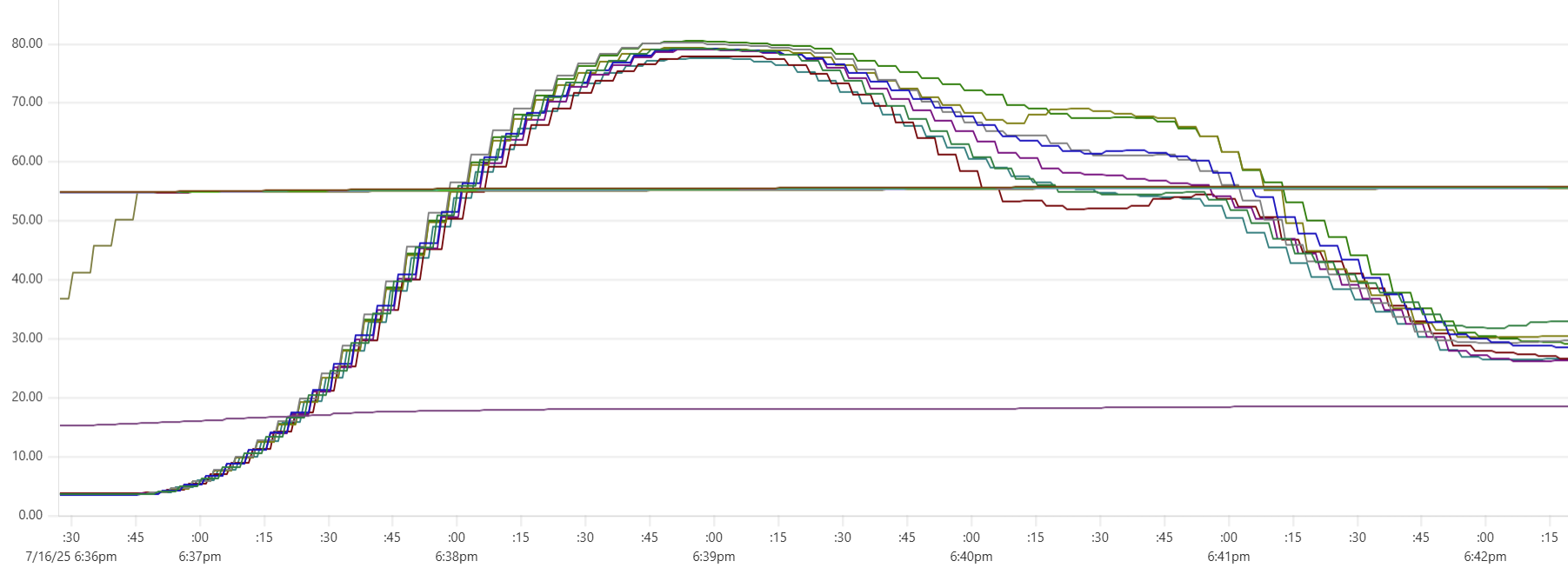
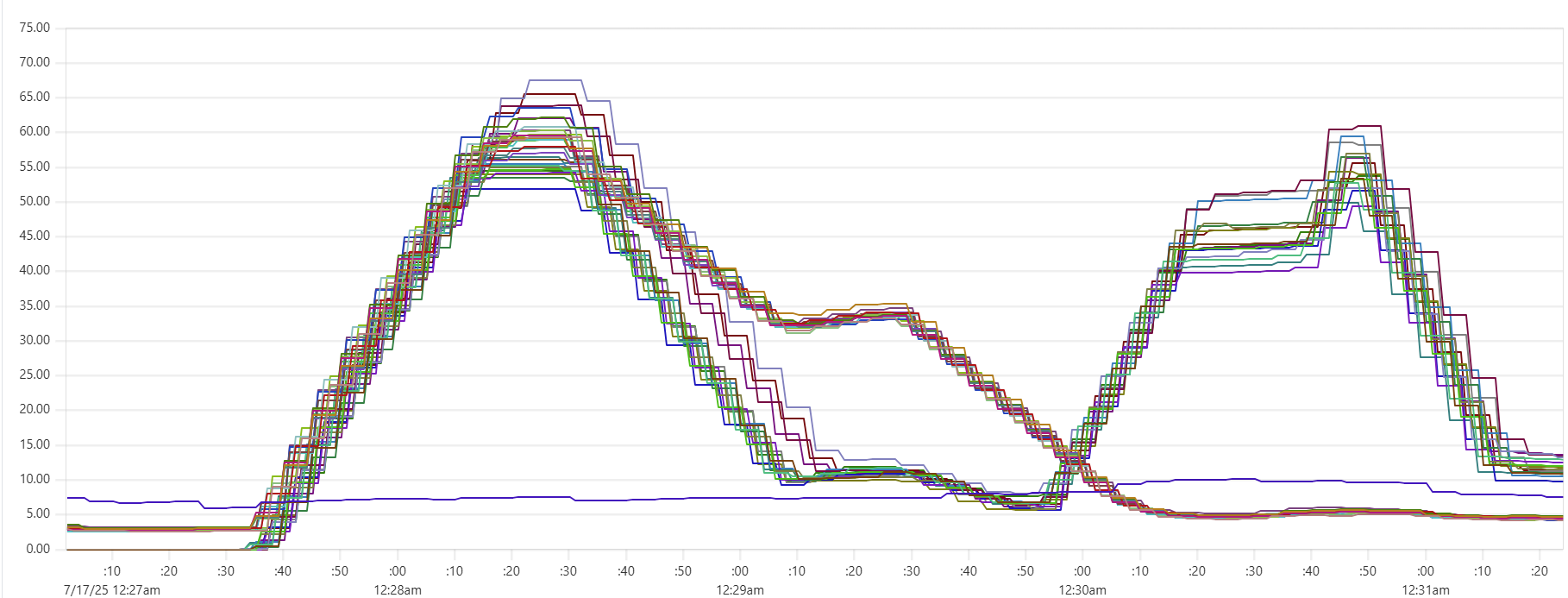
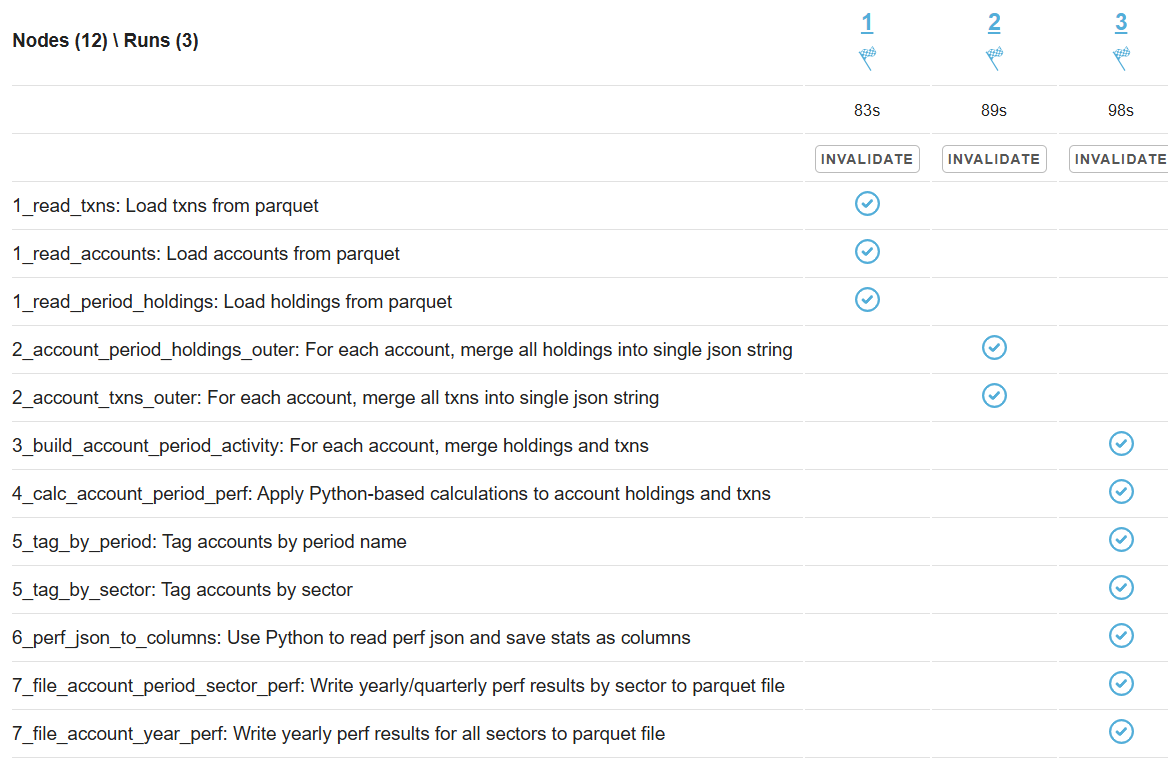
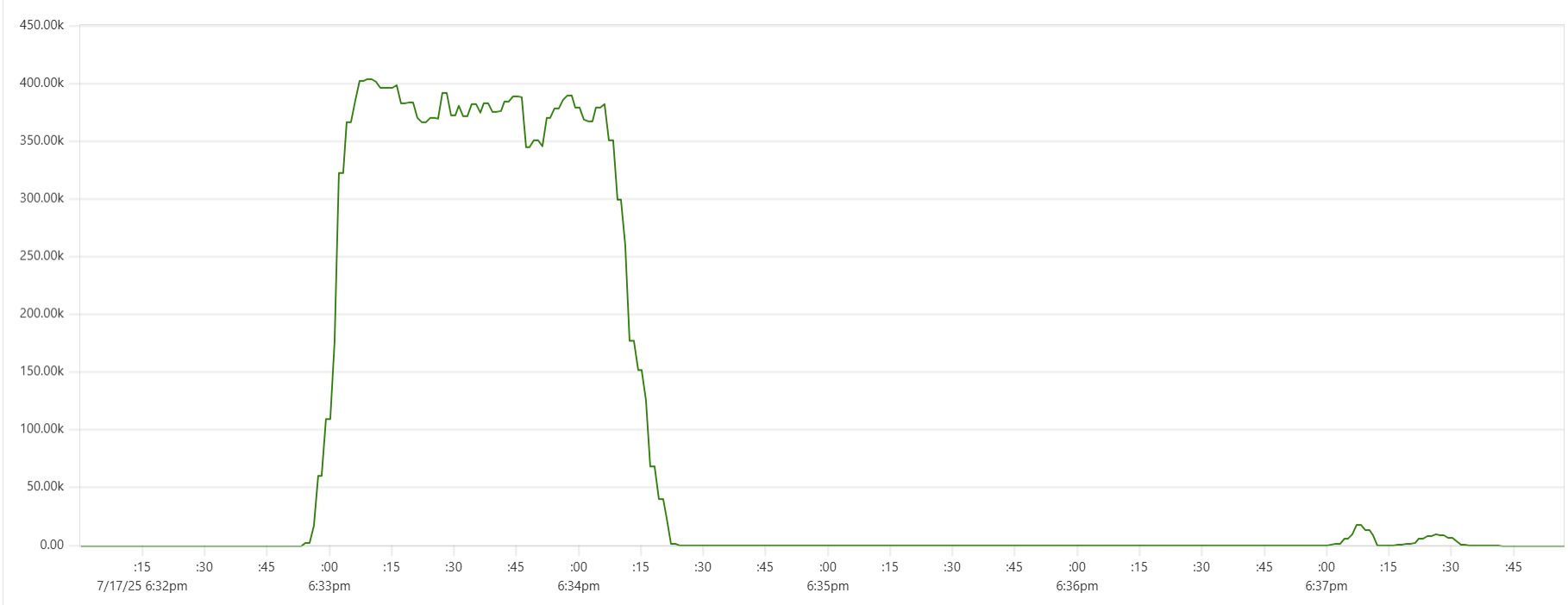
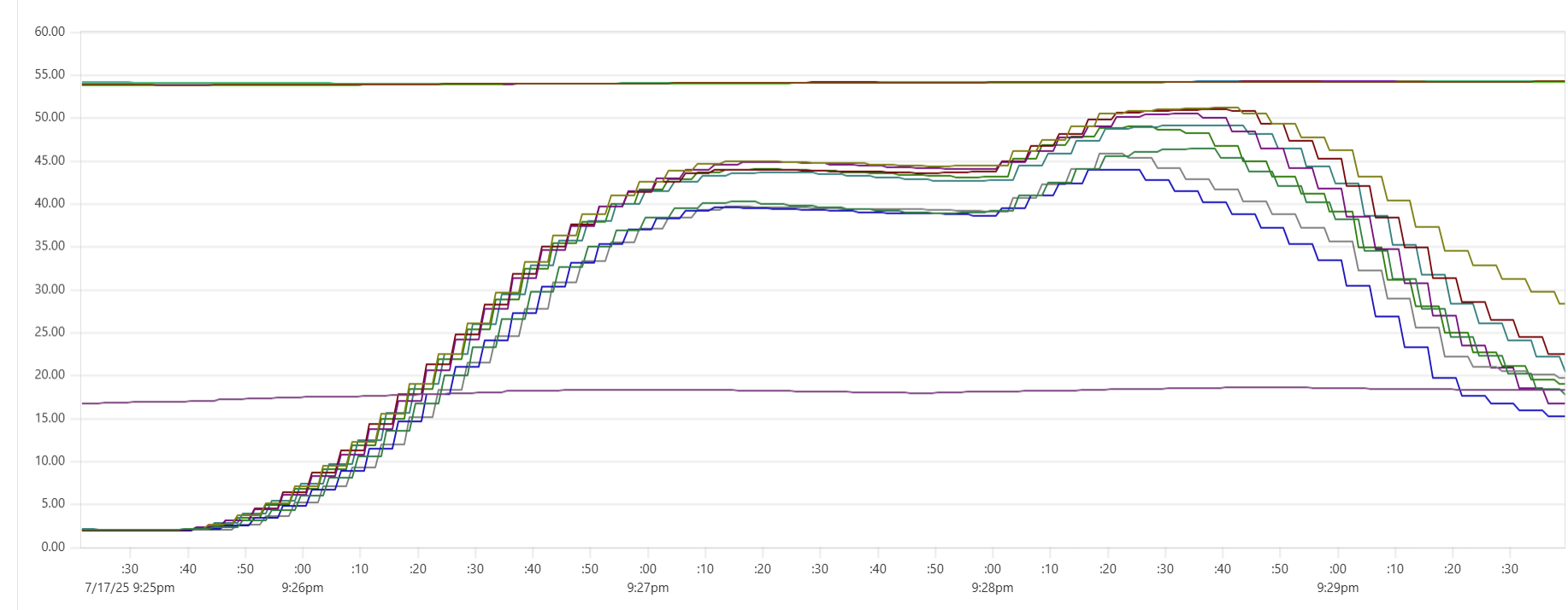
More expensive setups (with more instances or/and more powerful instances) complete the test faster, but tend to show higher cost per run. Why? Why is the black dot on both charts so far from the theoretical optimum? Here is the CPU usage profile for a 4-node Cassandra cluster with 64 cores per node:
The simple answer: we were not able to sufficiently engage the daemon instances or Cassandra nodes - CPU usage remained relatively low. But, again, why? There may be a number of explanations for that.
- Insufficient load: There are no clear “plateaus” in the CPU chart, which might suggest that the test dataset (14 million transactions) isn’t large enough to sustain high load. This is unlikely though - those CPU peaks at 80–90% suggest that the hardware was being put to work.
- Idle CPU due to batching: closer to the end of each of the three runs, CPU power may not be fully utilized because there's “no work” left for daemon threads between batches. Using a larger dataset with smaller batch sizes might make the right-hand slope of each phase “hill” steeper - more like a cliff.
- We may be hitting network performance ceilings. AWS instance types with an “n” offer higher bandwidth, and testing with these could confirm this theory.
- Unknown Capillaries design limitations: There may be architectural inefficiencies or bottlenecks in Capillaries that we haven’t yet identified.
There could be other factors. Further (more expensive) testing with larger datasets might provide answers.